























































These checks will enable us to understand the data, and so checks are the second most important step after the problem definition. Doing this will rule out some algorithms that won't perform well on some types of data:
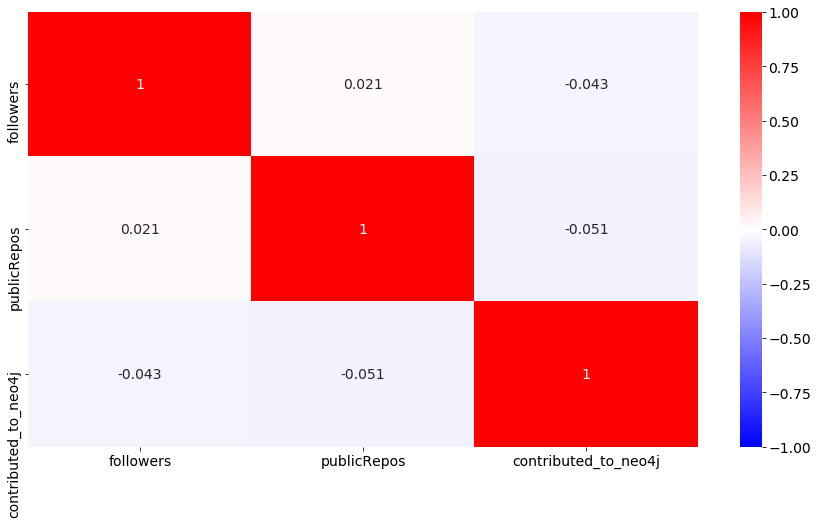
As the preceding matrix suggests, the correlation between our target variable, contributed_to_neo4j, and the two remaining features, publicRepos and followers, is quite low. This is also the case for the two features that weakly correlate to each other (0.021); this tells us that we can keep both of them and proceed to the next step.










