























































In the word embedding scenario, we generated the word context by pairing the word with all the words located close to it, within a given window size. However, graphs are not sequential, so how can we generate a context for nodes? The solution is to use random walks through the graph, with a given length.
Consider the graph represented in the following diagram on the left:
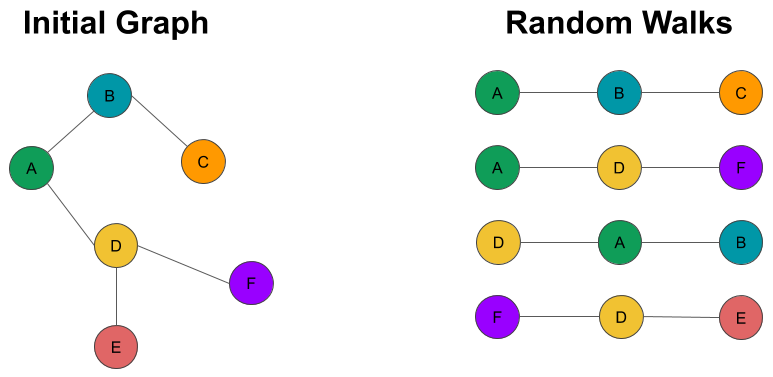
Starting from node A, we can generate paths of length 3 going through B then C, or starting from D and continuing to F for instance. The paths represented on the right in this diagram are the equivalent of the sentences in the context of text analysis. Using these sequences of nodes, we can now generate a training set and train a skip-gram model.
Before moving on from the topic of DeepWalk, let's extract the random walks from the GDS.










