























































When we have a dataset, it is preferred to use all of the observations available to train the model since, typically, more data results in better performances. By doing so, however, we take the risk of falling into a scenario where the model is perfectly able to model the data it has already seen, but will perform very badly with unseen data – this is referred to as the over-fitting scenario.
Take a look at the following plot:
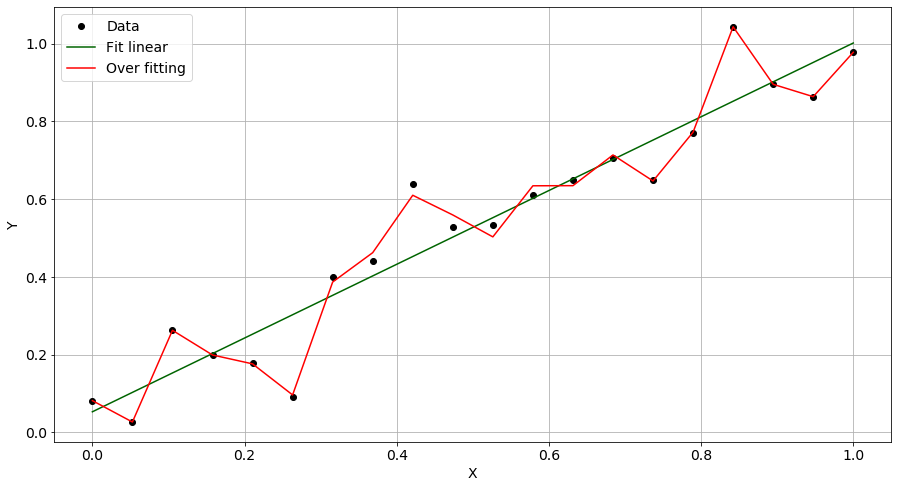
The observations are plotted with black dots and the green line represents the ground truth – that is, the real underlying model. The model whose results are displayed with the red line performs very well at predicting the values for the observed data but it will be poor at describing unseen data. In other words, it is over-fitted on the training set. To avoid this situation, we need to keep some observations apart that the model won't see at all during the training phase. Once the training is done,...










