























































CNNs and RNNs both involve aggregating information from a neighborhood in a special context. For RNNs, the context is a sequence of inputs (words, for instance) and a sequence is nothing more than a special type of graph. The same applies to CNNs, which are used to analyze images, or pixel grids, which are also a special type of graph where each pixel is connected to its adjacent pixels. It is logical therefore to try and use neural networks for all types of graphs (refer to the following diagram):
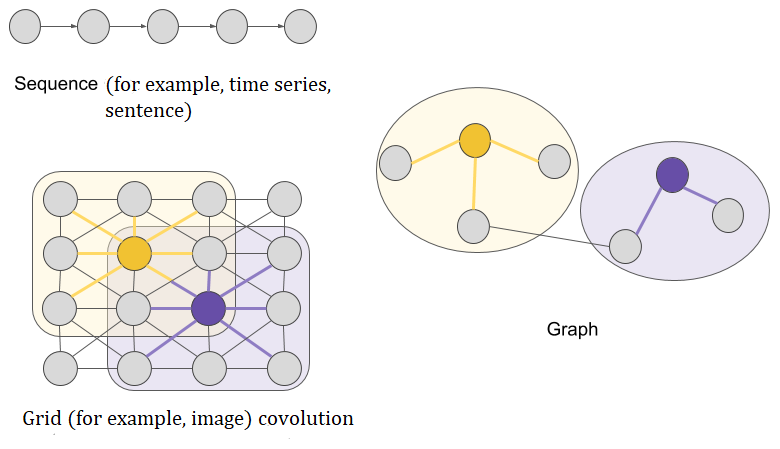
In order to find the embedding associated with each node, GNNs will use the data from that node but also from its neighbors in the graph.










