























































Let's consider the following quotation, uttered by the famous character Detective Sherlock Holmes in the novel A Study in Scarlett, by Arthur Conan Doyle:
First, we will simplify this sentence by removing words that do not provide any information, such as a and the (known as stop words in NLP) and remove the conjugate form of the verbs:
be capital mistake theorize before one have data
In most cases, we would also order words, let's say into alphabetical order, and remove duplicates, which would leave us with the following words to encode:
be before capital date have mistake one theorize
In order to represent each word of this corpus with a vector, we can use the one-hot encoding technique. This involves creating a vector of size equal to the number of words in the corpus, with zeros everywhere except at the index of the word. This is illustrated in the following diagram:
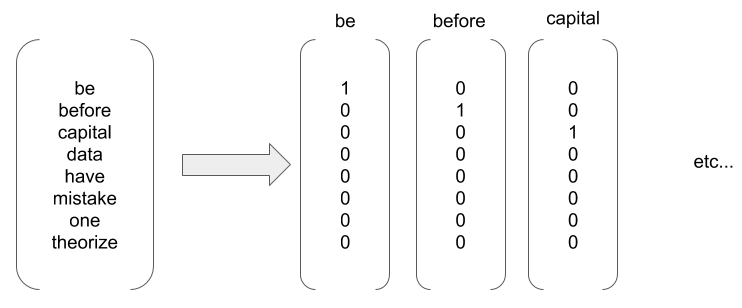
The word be is...










