























































Several variants of Label Propagation exist. The main idea is the following:
- Labels are initialized such that each node lies in its own community.
- Labels are iteratively updated based on the majority vote rule: each nodes receives the label of its neighbors and the most common label within them is assigned to the node. Conflicts appear when the most common label is not unique. In that case, a rule needs to be defined, which can be random or deterministic (like in the GDS).
- The iterative process is repeated until all nodes have fixed labels.
The optimal solution is a partition with the minimum number of edges connecting two nodes with different labels. Let's consider the following graph:
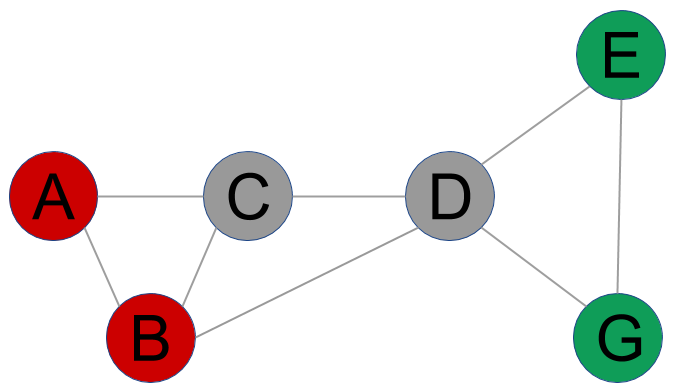
After some iterations, the algorithm assigned nodes A and B to one community (let's call it CR), and nodes E and G to another one (CG). According to the majority vote rule, in the next iteration, node C will be assigned to the CR community since two nodes connected...










