























































Using ZAP spider
In web applications, a crawler or spider is a tool that automatically goes through a website following all links in it and sometimes filling in and sending forms; this allows us to get a complete map of all of the referenced pages within the site and record the requests made to get them and their responses.
In this recipe, we will use ZAP's spider to crawl a directory in our vulnerable virtual machinevm_1and we will check on the information it captures.
How to do it...
We will use BodgeIt (http://192.168.56.11/bodgeit/) to illustrate how ZAP's spider works. Refer to the following steps:
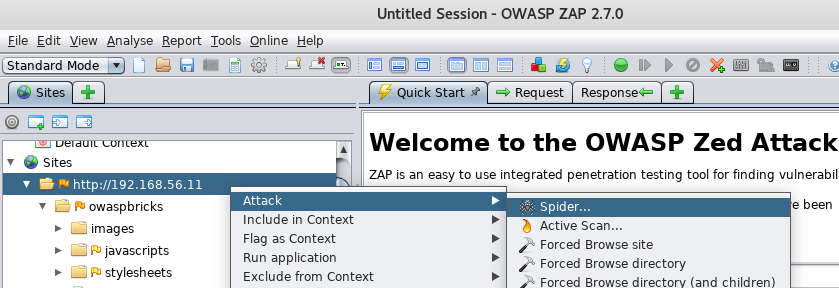
- In the
Sitestab, open the folder corresponding to the test site (http://192.168.56.11in this book). - Right-click on
GET:bodgeit. - From the drop-down menu select
Attack|Spider:
- In the
Spiderdialog, we can tell if the crawling will be recursive (spider inside the directories found), set the starting point, and other options. For now, we leave all default options as they are and clickStart Scan...















