Intel x86 (IA-32 and x64) is the most common architecture used in PCs and is powering many servers, so there is no surprise that most of the malware samples we have at the moment are supporting it. x86 is a CISC architecture, and it includes multiple complex instructions in addition to simple ones. In this section, we will introduce the most common of them, along with how compilers take advantage of them in their calling conventions.
Here is a table showing the relationship between registers in IA-32 and x64 architectures:
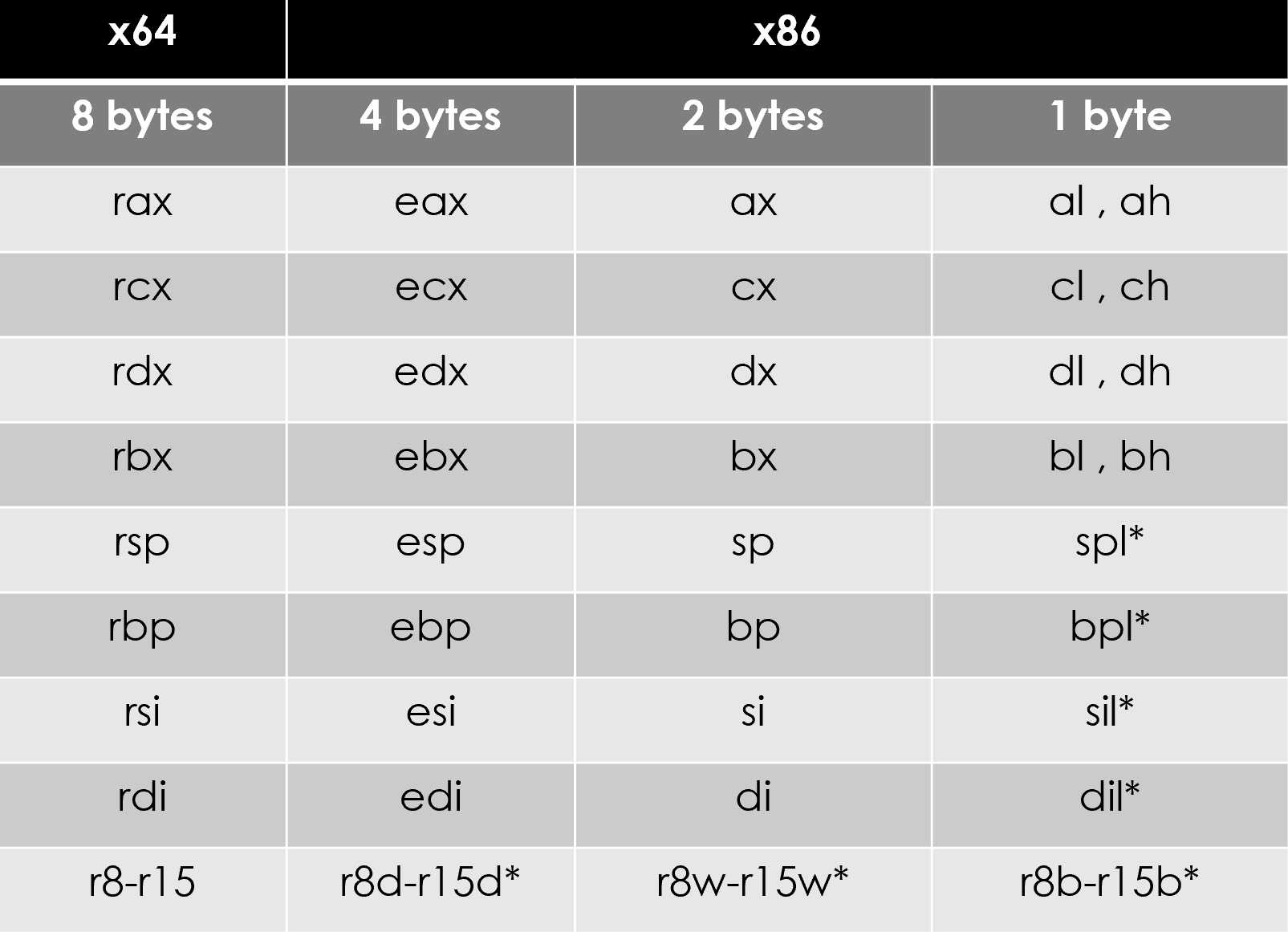
Figure 3: Registers used in the x86 architecture
r8 to r15 are available only in x64 and not in IA-32, and spl, bpl, sil, and dil can be accessed only in x64.
The first four registers (rax, rbx, rcx, and rdx) General-Purpose Registers (GPRs), but some of them have the following special use for certain instructions:
- rax/eax: This is used to store information and it's a special register for some calculations
- rcx/ecx: This is used as a counter register in loop instructions
- rdx/edx: This is used in division to return the modulus
In x64, the registers from r8 to r15 are also GPRs that were added to the available GPRs.
The rsp/esp register is used as a stack pointer that points to the top of the stack. It moves when there's a value getting pushed up, or down, when there's a value getting pulled out from the stack. The rbp/ebp register is used as a frame pointer, which means it points to the bottom of the stack and it's helpful for the function's local variable, as we will see later in this section. In addition to this, rbp/ebp is sometimes used as a GPR for storing any kind of data.
rsi/esi and rdi/edi are used mostly to define the addresses when copying a group of bytes in memory. The rsi/esi register always plays the role of the source and the rdi/edi register plays the role of the destination. Both registers are non-volatile and are also GPRs .
For Intel x86 assembly (IA-32 or x64), the common structure of its instructions is opcode, dest, and src.
Let's get deeper into them.
opcode is the name of the instruction. Some instructions have only opcode without any dest or src such as the following:
Nop, pushad, popad, movsb
pushad and popad are not available in x64.
dest represents the destination or where the result of the calculations will be saved, as well as becoming part of the calculations themselves like this:
add eax, ecx ;eax = (eax + ecx)
sub rdx, rcx ;rdx = (rdx - rcx)
Also, it could play a role of a source and a destination with some opcode instructions that take only dest without a source:
inc eax
dec ecx
Or, it could be only the source, such as these instructions that save the value to the stack like this:
push rdx
pop rcx
dest could look like the following:
- REG: A register such as eax and edx.
- r/m: A place in memory such as the following:
DWORD PTR [00401000h]
BYTE PTR [EAX + 00401000h]
WORD PTR [EDX*4 + EAX+ 30]
- A value in the stack (used to represent local variables), such as the following:
DWORD PTR [ESP+4]
DWORD PTR [EBP-8]
src represents the source or another value in the calculations, but it doesn't save the results afterward. It may look like this:
- REG: For instance, add rcx and r8
- r/m: For instance, add ecx and dword ptr [00401000h]
- imm: An immediate value such as mov eax and 00100000h
Here, we will cover the different types of instructions that we listed in the previous section.
Some of the arithmetic instructions are as follows:
|
Instruction
|
Structure
|
Description
|
|
add/sub
|
add/sub dest, src
|
dest = dest + src/dest = dest - src
|
|
inc/dec
|
inc/dec dest
|
dest = dest + 1/dest = dest - 1
|
|
mul
|
mul src
|
(Unsigned multiply) rdx:rax = rax* src
|
|
div
|
div src
|
rdx:rax/src (returns the result in rax and the remainder/modulus in rdx)
|
Additionally, for logic and bits manipulation, they are like this:
|
Instruction
|
Structure
|
Description
|
|
or/and/xor
|
or/and/xor dest, or src
|
dest = dest & src/dest = dest | src/dest = dest ^ src
|
|
not
|
not dest
|
dest = !dest (the bits are flipped)
|
And, lastly, for shifts and rotations they are like this:
|
Instruction
|
Structure
|
Description
|
|
shl/shr
|
shl/shr dest, imm, or cx
(the dest register's maximum number of bits such as 32 or 64)
|
dest = dest << src/dest = dest >> src
(shifts the dest register's bits to the left or the right, which is the same effect as multiplying or dividing by two src times)
|
|
rol/ror
|
shl/shr dest, imm, or cx
(same as shl and shr)
|
Rotates the dest register's bits left or right
|
There's a mov instruction, which copies a value from src to dest. This instruction has multiple forms, as we can see in this table:
|
Instruction
|
Structure
|
Description
|
|
mov
|
mov dest or src
|
dest = src
|
|
movsx/movzx
|
movsx/movzx dest or src
|
src is smaller than dest (src is 16-bits and dest is 32-bits)
movzx: Sets the remaining bits in dest to zero
movsx: Preserves the sign of the src value
|
Other instructions related to stack are like this:
|
Instruction
|
Structure
|
Description
|
|
push/pop
|
push/pop dest
|
Pushes the value on to the top the stack (esp = esp -4)/
pulls the value out of the stack (esp = esp + 4)
|
|
pushad/popad
|
pushad/popad
|
Saves all registers to the stack/pulls out all registers from the stack (in x86 only)
|
For string manipulation, they are like this:
| Instruction |
Structure |
Description |
| lodsb/lodsw/lodsd/lodsq |
lodsb/lodsw/lodsd/lodsq |
Loads a byte, 2 bytes, 4 bytes, or 8 bytes from rsi/esi into al/ax/eax/rax |
| stosb/stosw/stosd/stosq |
stosb/stosw/stosd/stosq |
Stores a byte, 2 bytes, 4 bytes, or 8 bytes in rdi/edi from al/ax/eax/rax |
| movsb/movsw/movsd/movsq |
movsb/movsw/movsd/movsq |
Copy a byte, 2 bytes, 4 bytes, or 8 bytes from rsi/esi to rdi/edi |
Some of the unconditional redirections are as follows:
| Instruction |
Structure |
Description |
| jmp |
jmp <relative address>
jmp DWORD/QWORD ptr [Absolute Address] |
The relative address is calculated from the start of the next instruction after jmp to the destination |
| call |
call <relative address>
call DWORD/QWORD ptr [Absolute Address]
|
Same as jmp but it saves the return address in the stack |
| ret/retn |
ret imm |
Pulls the return address from the stack, cleans the stack from the pushed arguments, and jumps to that address |
Some of the conditional redirections are as follows:
| Instruction |
Structure |
Description |
| jnz/jz/jb/ja |
jz/jnz <relative address> |
Similar to jmp, but jumps based on a condition |
| loop |
loop <relative address> |
Similar to jmp, but it decrements rcx/ecx and jumps if it didn't reach zero (uses rcx/ecx as a loop counter) |
| rep |
rep opcode dest or src (if needed) |
rep is a prefix that is used with string instructions; it decrements rcx/ecx, and repeats the instruction until rcx/ecx reaches zero |
There are multiple ways in which the compilers represent functions, calls, local variables, and more. We will not be covering all of them, but we will be covering some of them. We will cover standard call (stdcall), which is only used in x86, and then we will be covering the differences between the other calls and stdcall.
The stack, rsp/esp, and rbp/ebp registers do most of the work when it comes to arguments and local variables. The call instruction saves the return address at the top of the stack before transferring the execution to the new function, and the ret instruction at the end of the function returns the execution back to the caller function using the return address saved in the stack.
For stdcall, the arguments are also pushed in the stack from the last argument to the first like this:
Push Arg02
Push Arg01
Call Func01
In the call function, the arguments can be accessed by rsp/esp but keeping in mind how many values have been pushed to the top of the stack through time with something like this:
mov eax, [esp + 4] ;Arg01
push eax
mov ecx, [esp + 8] ; Arg01 keeping in mind the previous push
In this case, the value located at the address specified by the value inside the square brackets is transferred. Fortunately, modern static analysis tools, such as IDA Pro, can detect which argument is being accessed in each instruction, as in this case.
The most common way to access arguments, as well as local variables, is by using rbp/ebp. First, the called function needs to save the current rsp/esp in rbp/ebp register and then access them this way:
push ebp
mov ebp, esp
...
mov ecx, [ebp + 8] ;Arg01
push eax
mov ecx, [ebp + 8] ;still Arg01 (no changes)
And, at the end of the called function, it returns back the original value of rbp/ebp and the rsp/esp like this:
mov esp,ebp
pop ebp
ret
As it's a common function epilogue, Intel created a special instruction for it, which is leave, so it became this:
leave
ret
For local variables, the called function allocates space for them by shifting the rsp/esp instruction up. To allocate space for two variables of four bytes each, the code will be this:
push ebp
mov ebp,esp
sub esp, 8
Additionally, the end of the function will be this:
mov ebp,esp
pop ebp
ret
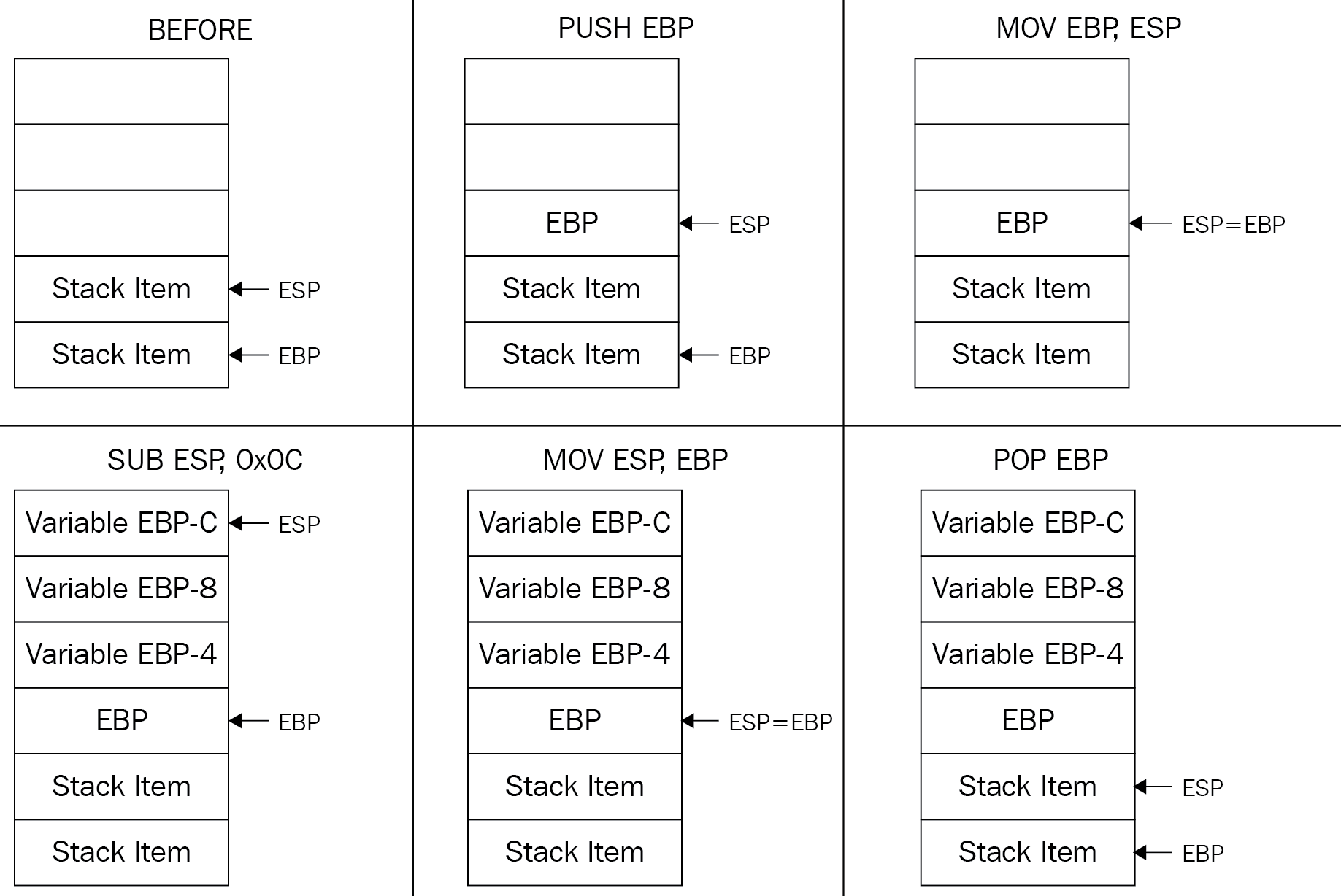
Figure 4: An example of a stack change at the beginning and at the end of the function
Additionally, if there are arguments, the ret instruction cleans the stack given the number of bytes to pull out from the top of the stack like this:
ret 8 ;2 Arguments, 4 bytes each
cdecl (which stands for c declaration) is another calling convention that was used by many C compilers in x86. It's very similar to stdcall, with the only difference being that the caller cleans the stack after the callee function (the called function) returns like this:
Caller:
push Arg02
push Arg01
call Callee
add esp, 8 ;cleans the stack
The __fastcall calling convention is also widely used by different compilers, including Microsoft C++ compiler and GCC. This calling convention passes the first two arguments in ecx and edx, and pushes the remaining arguments in the stack. It's only used in x86 as there's only one calling convention for x64.
For object-oriented programming and for the non-static member functions (such as the classes' functions), the C compiler needs to pass the address of the object whose attribute will be accessed or manipulated using this function as an argument.
In GCC compiler, this call is almost identical to the cdecl calling convention and it passes the object address as a first argument. But in the Microsoft C++ compiler, it's similar to stdcall and it passes the object address in ecx. It's common to see such patterns in some object-oriented malware families.
In x64, the calling convention is more dependent on the registers. For Windows, the caller function passes the first four arguments to the registers in this order: rcx, rdx, r8, r9, and the rest are pushed back to the stack. While for the other operating systems, the first six arguments are usually passed to the registers in this order: rsi, rdi, rcx, rdx, r8, r9, and the remaining to the stack.
In both cases, the called function cleans the stack after using ret imm, and this is the only calling convention for these operating systems in x64.

 United States
United States
 Great Britain
Great Britain
 India
India
 Germany
Germany
 France
France
 Canada
Canada
 Russia
Russia
 Spain
Spain
 Brazil
Brazil
 Australia
Australia
 South Africa
South Africa
 Thailand
Thailand
 Ukraine
Ukraine
 Switzerland
Switzerland
 Slovakia
Slovakia
 Luxembourg
Luxembourg
 Hungary
Hungary
 Romania
Romania
 Denmark
Denmark
 Ireland
Ireland
 Estonia
Estonia
 Belgium
Belgium
 Italy
Italy
 Finland
Finland
 Cyprus
Cyprus
 Lithuania
Lithuania
 Latvia
Latvia
 Malta
Malta
 Netherlands
Netherlands
 Portugal
Portugal
 Slovenia
Slovenia
 Sweden
Sweden
 Argentina
Argentina
 Colombia
Colombia
 Ecuador
Ecuador
 Indonesia
Indonesia
 Mexico
Mexico
 New Zealand
New Zealand
 Norway
Norway
 South Korea
South Korea
 Taiwan
Taiwan
 Turkey
Turkey
 Czechia
Czechia
 Austria
Austria
 Greece
Greece
 Isle of Man
Isle of Man
 Bulgaria
Bulgaria
 Japan
Japan
 Philippines
Philippines
 Poland
Poland
 Singapore
Singapore
 Egypt
Egypt
 Chile
Chile
 Malaysia
Malaysia




















