























































Crawling the web application using Burp Spider
The idea here is simple: all you need to know is how to find all of the pages for the web application of your target scope. There are three ways to accomplish this task:
- Manually crawling by using the Intruder tool
- Automatically crawling by using Burp Spider
- Automatically finding hidden items by using the Discover Content tool
Manually crawling by using the Intruder tool
In some cases you want to run a manual crawling using one of the predefined dictionary file, to do this perform the following steps:
- Select the root path; in our example, it's
mutillidae, because this is our starting point for crawling. Next, right-click on the request and send it to theIntrudertab:
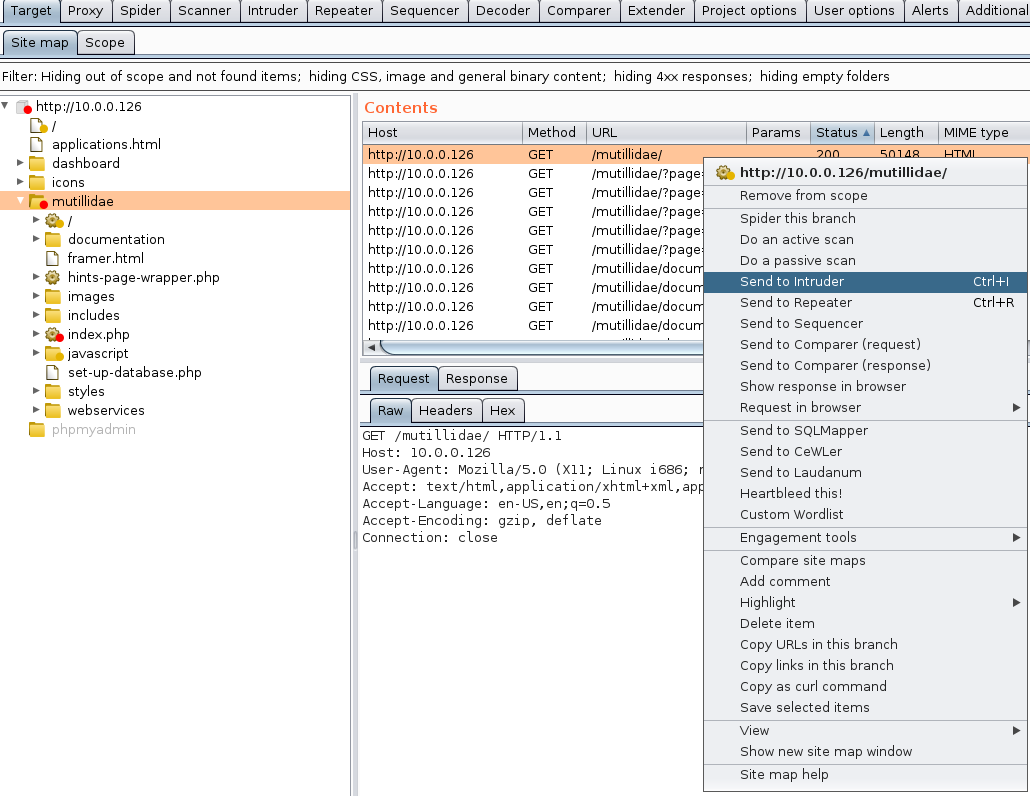
- At this point, the
Intrudertab will start blinking, which tells you that it's ready (let's click on theIntrudertab). The first thing that you will encounter in theIntrudertab is theTargetsection; leave it as it is, and move on to thePositionssection:
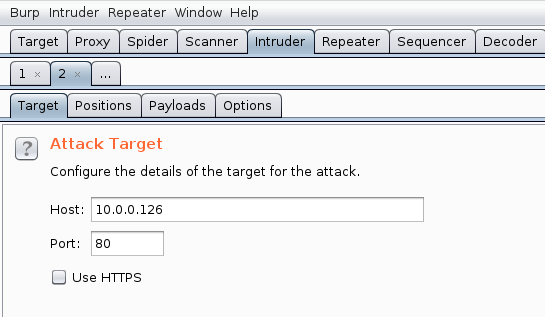
- In the
Positionssub-tab,...















