























































Binary communication – direct communication between services
Much is discussed about microservices communication; topics such as protocols, layers, types, and package sizes are widely discussed when it comes to the subject.
The point is that communication between microservices is the most critical topic for project success. It is very clear that the amount of positive factors increases with microservices architecture, but how to make the communication that does not encumber the performance of a product to the end user is the key point.
It does not help that all the practicalities of developing and deploying the product do not scale or the end user experience is compromised.
There is a lot of literature and study material on the subject, but the challenge still remains. And oddly enough, even with all the available material, making mistakes in this part of the project is extremely easy.
There are only two forms of communication between microservices. These forms are synchronous and asynchronous. The most common is asynchronous communication between microservices, as it is easier to scale but it is harder to understand possible error points. Using synchronous forms of communication between microservices, it is easier to understand the possible errors in this area, but it is more difficult to scale. In this segment, we will deal with synchronous communication.
Understanding the aspect
The first step is to understand the functioning of the microservice to know what kind of communication best applies. Take, for example, the microservice recommendations. It is a microservice that has no direct communication with the customer, but traces a user's profile. No other application point expects an immediate response arising from this microservice. Thus, the communication model for this microservice is asynchronous.
Very well! We saw that RecommendationService is not a synchronous case; then what is?
The answer is UserService. When a user enters a given API that communicates with UserService, this user sees the change immediately. When a microservice requests some information on the requested UserService, we want the most current information possible and immediately. Yes, UserService is a service where synchronous communication can be applied.
But how can we create a good layer of synchronous communication between microservices? The answer is right in the next section.
Tools for synchronous communication
The most common form of direct communication between microservices is using the HTTP protocol with Rest and passing JavaScript Object Notation, the famous JSON. Communication works great for APIs, providing endpoints for external consumption. However, communication using HTTP with JSON has a high cost in relation to performance.
First, this is because in the case of communication between microservices, it would be more appropriate to optimize than the HTTP protocol creating some sort of pipeline or keeping the connection alive. The problem is the control of the connection timeout, which shouldn't be very strict, and in addition could start to close doors, threads, or processes with a simple silent error. The second problem with this approach is the serialization time of JSON sent. Normally this is not an inexpensive process. Finally, we have the packet size sent to the HTTP protocol. In addition to JSON, there are a number of HTTP headers that should be interpreted further which may be discarded. Look closer; there's no need to elaborate on protocols between microservices, the only concern should be to maintain a single layer for sending and receiving messages. Therefore, the HTTP protocol with JSON to communicate between microservices can be a serious slow point within the project and, despite the practicality of implementation of the protocol, the optimization is complex to understand yet not very significant.
Many would propose the implementation of communication sockets or WebSockets but, in the end, the customization process of these communication layers is very similar to the classic HTTP.
Synchronous communication layers between microservices must complete three basic tasks:
- Report practice and direct the desired messages
- Send simple, lightweight packages and fast serialization
- Be practical to maintain the signature of communication endpoints
A proposal that meets the aforementioned requirements communicates using binary or small-size packages.
Something important to point out when it comes to working with this type of protocol is that, usually, they are incompatible with each other. This means that the option chosen as the tool for serialization and submission of these small-sized packages should be compatible with the stack of all microservices.
Some of the most popular options on the market are:
- MessagePack (http://msgpack.org/)
- gRPC (https://grpc.io/)
- Apache Avro (https://avro.apache.org/)
- Apache Thrift (https://thrift.apache.org/)
Let us understand how each of these options works to see what best fits on our news portal.
MessagePack
The MessagePack or MsgPack is a type of serializer for binary information, but, as the official tool's own website says, "It's like JSON, but fast and small."
The proposed MsgPack is serializing data quickly and with reduced size, thus offering a more efficient package for communication between microservices. At first, the MsgPack was not more efficient than the other serializers, but this problem has been overcome with this change.
When it comes to compatibility between the programming languages, MsgPack is very good; it just has a library of the most well-known languages of the market. The offer goes from Python libraries to Racket, for example.
The MsgPack does not have a native tool in the shipping package; it is left to the developer. This can be a problem because a layer of communication between microservices that supports multilingual stacks still needs to be found.
gRPC
The gRPC has a more complete proposal than MsgPack because it is composed of the data serializer Protobuf, as a layer between communication services making use of RPC.
For serialization, create a .proto file with the information about what will be serialized for RPC communication following a client/server model if needed.
The following code can be seen as an example of a .protocol file, that was extracted from the official site tool:
The greeting service definition:
service Greeter { Sends a greeting:
rpc SayHello (HelloRequest) returns (HelloReply) {}
} The request message containing the user's name:
message HelloRequest {
string name = 1;
} The response message containing the greetings:
message HelloReply {
string message = 1;
} The file .proto has a specific form of writing. The positive aspect of a file like this is that the signing of the communication layer is normalized because, at some level, the file created as the serialization template and creating clients/servers ends up serving as the documentation of endpoints.
After the file is created, to create the communication part you need only run a command line. The following example creates the client/server in Python:
$ python -m grpc_tools.protoc -I../../protos --python_out=. --grpc_python_out=. ../../protos/file_name.protoThe command may seem a little intimidating at first but is enough to generate a client and server RPC of communication. The gRPC has evolved a lot and received strong investment.
With regards to the compatibility, gRPC does not meet the same requirements that MsgPack does, but has compatibility with the most commonly used languages in the market.
Apache Avro
Avro is one of the most mature and experienced serialization systems for binary. As with gRPC, Avro also has a communication layer using RPC.
Avro uses a .avsc file, which is defined in JSON format, for the serialization process. The file may be composed of both types that provide JSON, or more complex types from Avro itself.
Even being very mature as a tool, Avro is the poorest in terms of native compatibility with other programming languages other than Java, Ruby, C++, C#, and Python. As the project is open source, there is a whole range of drivers that provide compatibility with Avro that come from the community.
Apache Thrift
Thrift is a project created by Facebook and maintained by the Apache Software Foundation. It has a good level of compatibility with the languages most commonly used in the market of programming.
Thrift has the communication layer with RPC and a part of serialization using a file .thrift as a template. The file .thrift has notation and types similar to the C++ language in which Thrift was developed.
An example of file .thrift can be viewed in the following:
typedef i32 MyInteger
const i32 INT32CONSTANT = 9853
const map<string,string> MAPCONSTANT = {'hello':'world',
'goodnight':'moon'}
enum Operation {
ADD = 1,
SUBTRACT = 2,
MULTIPLY = 3,
DIVIDE = 4
}
struct Work {
1: i32 num1 = 0,
2: i32 num2,
3: Operation op,
4: optional string comment,
}
exception InvalidOperation {
1: i32 whatOp,
2: string why
}
service Calculator extends shared.SharedService {
void ping(),
i32 add(1:i32 num1, 2:i32 num2),
i32 calculate(1:i32 logid, 2:Work w) throws
(1:InvalidOperation ouch),
oneway void zip()
}
Do not worry about the file contents. The important thing is realizing the flexibility that is offered by the RPC Thrift composition. An interesting point to note is the following line of code:
service Calculator extends shared.SharedService { ... Thrift allows the use of inheritance among the template files, which will be used by code generators.
To create the client/server using Thrift, simply use the following command line:
$ thrift -r --gen py file_name.thriftThe preceding line will create a client and server in the Python programming language.
Among the options presented, the most common at the moment are Thrift and gRPC, and any one of these tools is a good deployment option for direct communication between microservices.
Direct communication alerts
Direct communication between microservices may result in a problem known as Death Star. The Death Star is an anti-pattern where there is communication between the recursion microservices, and making progress becomes extremely complicated or expensive for a product.
With the communication tools we saw previously, it is very easy to establish conversations between microservices with low latency. The common anti-pattern is to allow microservices to exchange messages with each other freely, if they have no information to process a specific task.
This is where we have an alert. If a microservice always needs to communicate with another to complete a task, it is a high coupling signal and we have failed in our DDD process. This engagement results in a Death Star. For clarity, consider the following scenario.
Imagine that we have four microservices. The microservices are A, B, C, and D. A request was made asking for information about A, but it does not have all the information content. This content is in B and C, but C does not have all of the information, so it asks D. B is not able to complete the task assigned to him and asks for data from C. However, D needs the data in A. The following is a diagrammatic representation of this process:
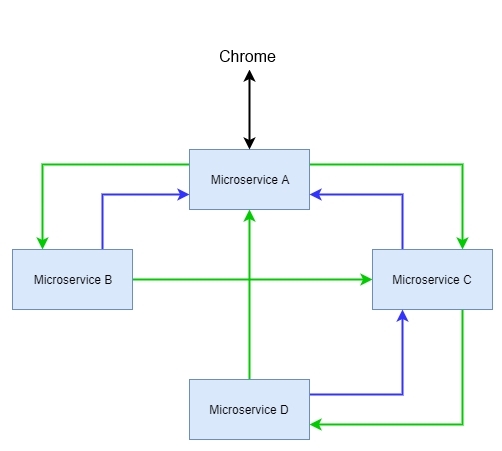
In the end, a simple request generates a very complex flow, where any failure is difficult to monitor. Apparently, it may seem natural, but over time and with the creation of new microservices, it makes this ecosystem unsustainable.
The microservices must be sufficiently well defined in their respective responsibilities for this type of messaging to be minimized.
No matter how fast the communication and serialization information is, if the product is not humanly intelligible and understandable, it will be very difficult to maintain the ecosystem of microservices, especially with regards to error control.






