























































How a network learns
Suppose we have a two-layer network. Let’s represent inputs/outputs with
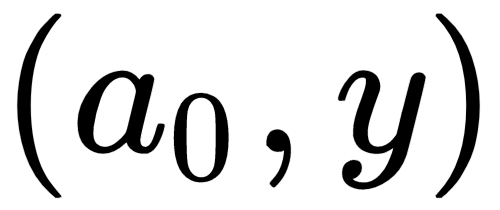
, and the two layers by states, that is, the connection weights with bias value:
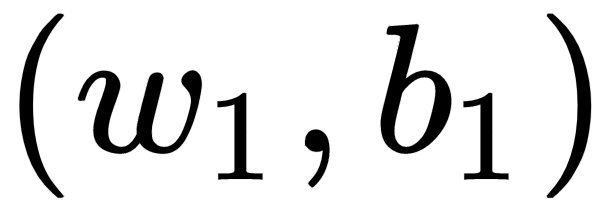
and
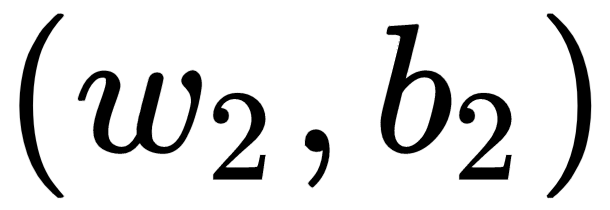
. We will also use σ as the activation function.
Weight initialization
After the configuration of the network, training starts with initializing the weights' values. A proper weight initialization is important in the sense that all the training does is to adjust the coefficients to best capture the patterns from data in order to successfully output the approximation of the target value. In most cases, weights are initialized randomly. In some finely-tuned settings, weights are initialized using a pre-trained model.
Forward propagation
Forward propagation is basically calculating the input data multiplied by the networks’ weight plus the offset, and then going through the activation function to the next layer:
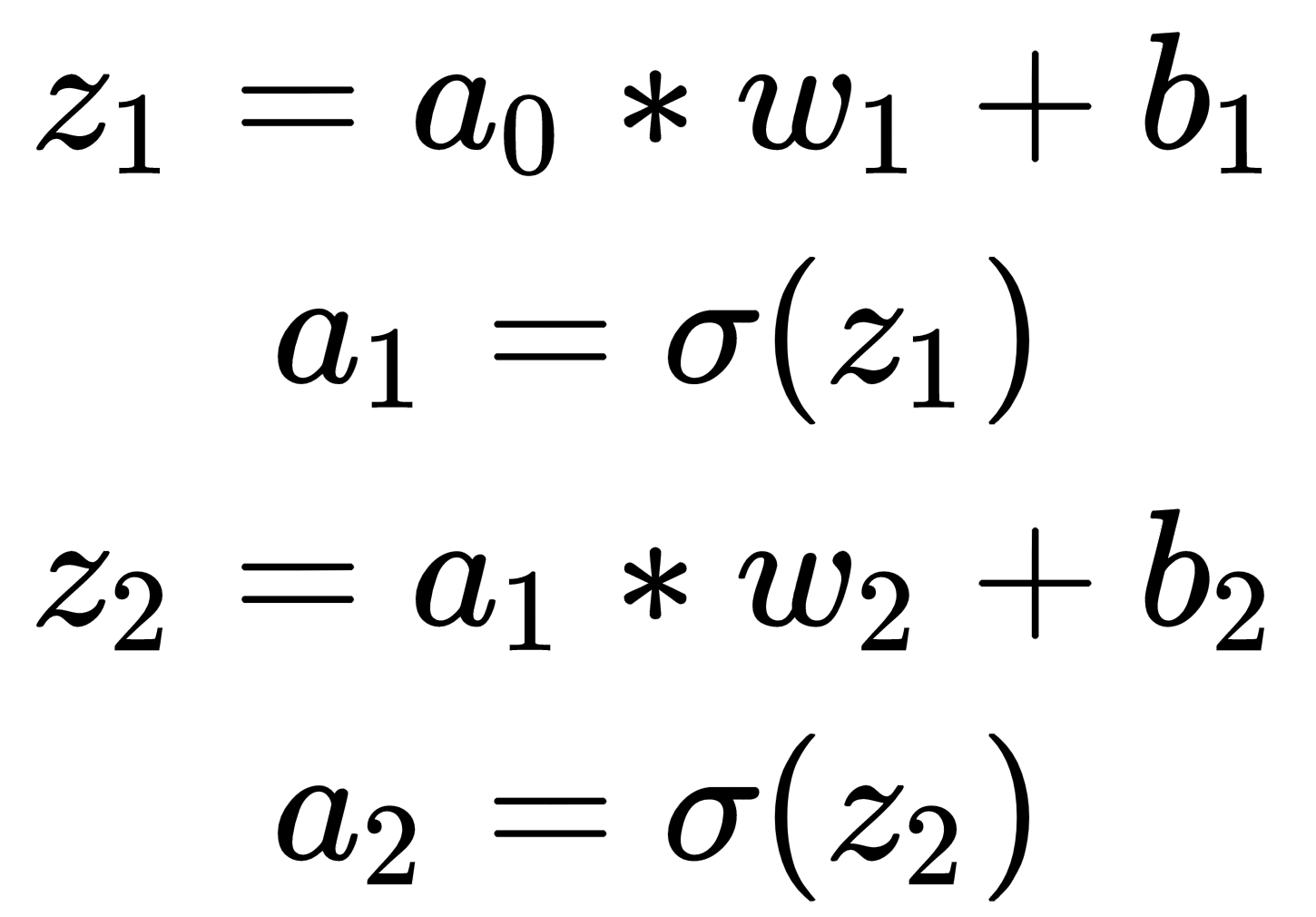
An example code block using TensorFlow can be written as follows:
# dimension variables dim_in = 2 dim_middle...

















