























































Hadoop MapReduce
Now that we have an understanding of how HDFS works, it's time to move forward and seek to understand what the benefit of HDFS and a clustered computing environment is. Hadoop introduces the MapReduce framework to facilitate the execution of programs and parallel processing. The following figure illustrates where the MapReduce framework fits into Hadoop's architecture:
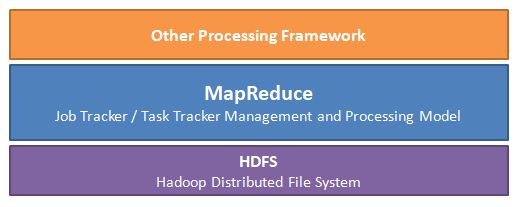
Figure-3.2.5
This framework mainly consists of two parts: Map and Reduce. The Map process mainly comprises of getting information from the data stored, applying the required algorithm, and generating a result in the form of key-value pairs. The Reduce process is used to summarize the information that was collected and paired during the Map process. We will look at these processes in more detail as we proceed with this chapter, but let's first understand how a program is executed in Hadoop.
Job Tracker and Task Tracker
Similar to HDFS, there are two main processes involved in the execution of any program, which...












