























































The silhouette method assesses and validates cluster data. It finds how well each data point is classified. The plot of the silhouette score helps us to visualize and interpret how well data points are tightly grouped within their own clusters and separated from others. It helps us to evaluate the number of clusters. Its score ranges from -1 to +1. A positive value indicates a well-separated cluster and a negative value indicates incorrectly assigned data points. The more positive the value, the further data points are from the nearest clusters; a value of zero indicates data points that are at the separation line between two clusters. Let's see the formula for the silhouette score:
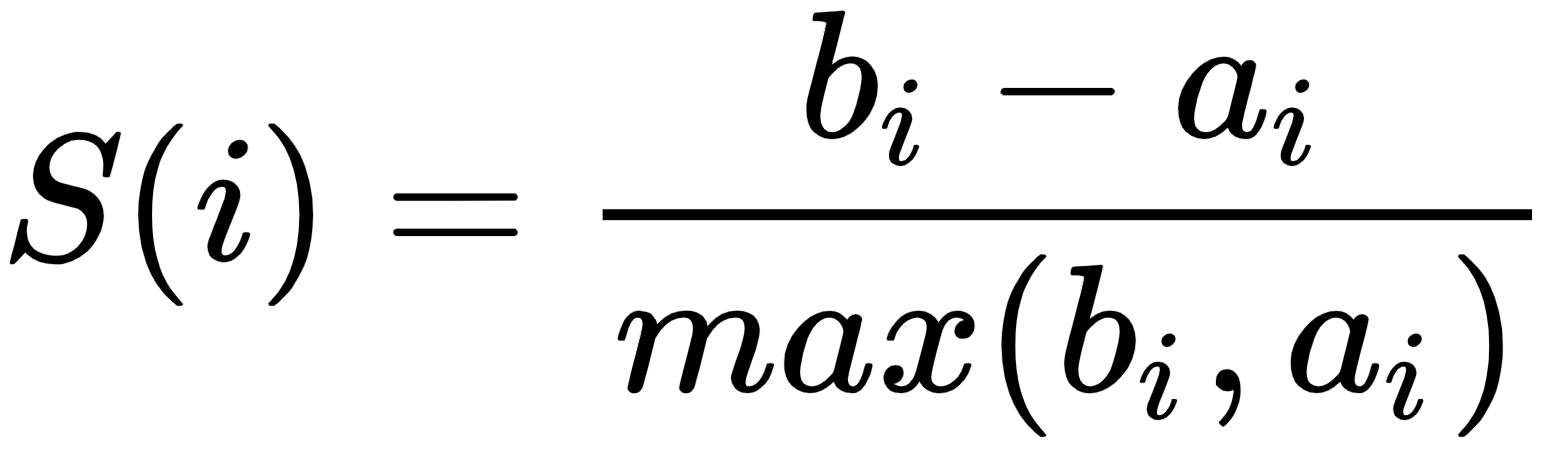
ai is the average distance of the ith data point from other points within the cluster.
bi is the average distance of the ith data point from other cluster points.
This means we can easily say that S(i) would be between [-1, 1]. So, for S(i) to be near to 1, ai must...
















