























































The Fowlkes-Mallows score is a geometric mean of precision and recall. A high value represents similar clusters. This can be calculated as follows:
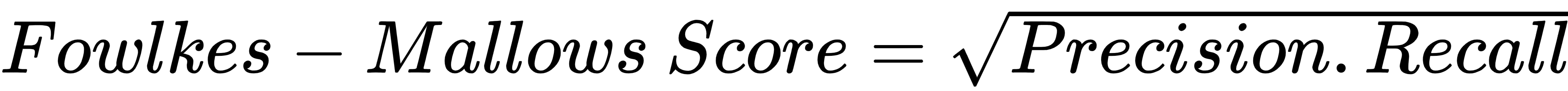
Let's create a cluster model using k-means clustering and evaluate the performance using the internal and external evaluation measures in Python using the Pima Indian Diabetes dataset (https://github.com/PacktPublishing/Python-Data-Analysis-Third-Edition/blob/master/Chapter11/diabetes.csv):
# Import libraries
import pandas as pd
# read the dataset
diabetes = pd.read_csv("diabetes.csv")
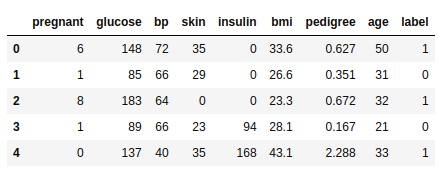
# Show top 5-records
diabetes.head()
This results in the following output:
First, we need to import pandas and read the dataset. In the preceding example, we are reading the Pima Indian Diabetes dataset:
# split dataset in two parts: feature set and target label
feature_set = ['pregnant', 'insulin', 'bmi', 'age','glucose','bp','pedigree']
features...
















