























































Hadoop MapReduce
Apache MapReduce is a framework that makes it easier for us to run MapReduce operations on very large, distributed datasets. One of the advantages of Hadoop is a distributed file system that is rack-aware and scalable. The Hadoop job scheduler is intelligent enough to make sure that the computation happens on the nodes where the data is located. This is also a very important aspect as it reduces the amount of network IO.
Let's see how the framework makes it easier to run massively parallel computations with the help of this diagram:
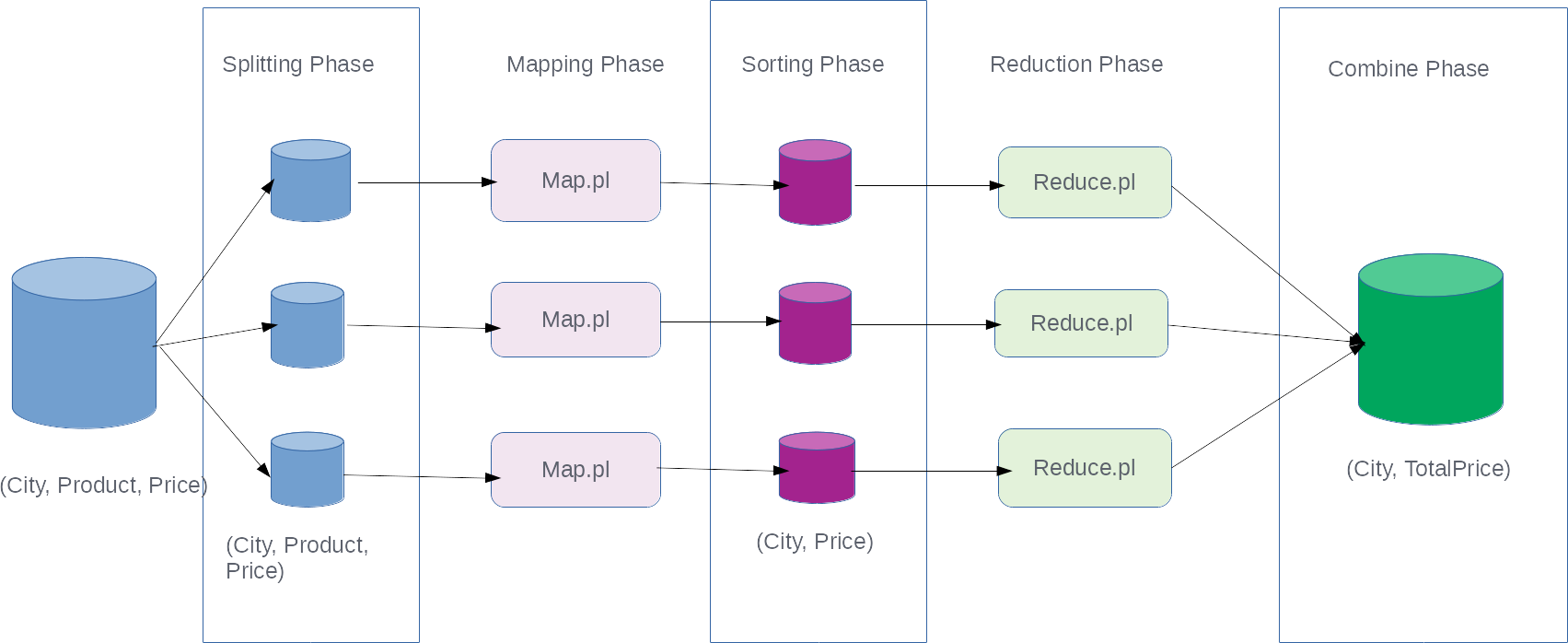
This diagram looks a bit more complicated than the previous diagram, but most of the things are done by the Hadoop MapReduce framework itself for us. We still write the code for mapping and reducing our input data.
Let's see in detail what happens when we process our data with the Hadoop MapReduce framework from the preceding diagram:
- Our input data is broken down into pieces
- Each piece of the data is fed to a mapper program
- Outputs from all the mapper...

















