























































Training stability
Different methods are possible to improve stability during training. Online training, that is, training the model while playing the game, forgetting previous experiences, just considering the last one, is fundamentally unstable with deep neural networks: states that are close in time, such as the most recent states, are usually strongly similar or correlated, and taking the most recent states during training does not converge well.
To avoid such a failure, one possible solution has been to store the experiences in a replay memory or to use a database of human gameplays. Batching and shuffling random samples from the replay memory or the human gameplay database leads to more stable training, but off-policy training.
A second solution to improve stability is to fix the value of the parameter 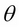 in the target evaluation
in the target evaluation 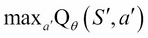 for several thousands of updates of
for several thousands of updates of 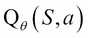 , reducing the correlations between the target and the Q-values:
, reducing the correlations between the target and the Q-values:
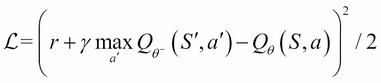
It is possible to train more efficiently with n-steps Q-learning...

















