























































Optimization and other update rules
Learning rate is a very important parameter to set correctly. Too low a learning rate will make it difficult to learn and will train slower, while too high a learning rate will increase sensitivity to outlier values, increase the amount of noise in the data, train too fast to learn generalization, and get stuck in local minima:
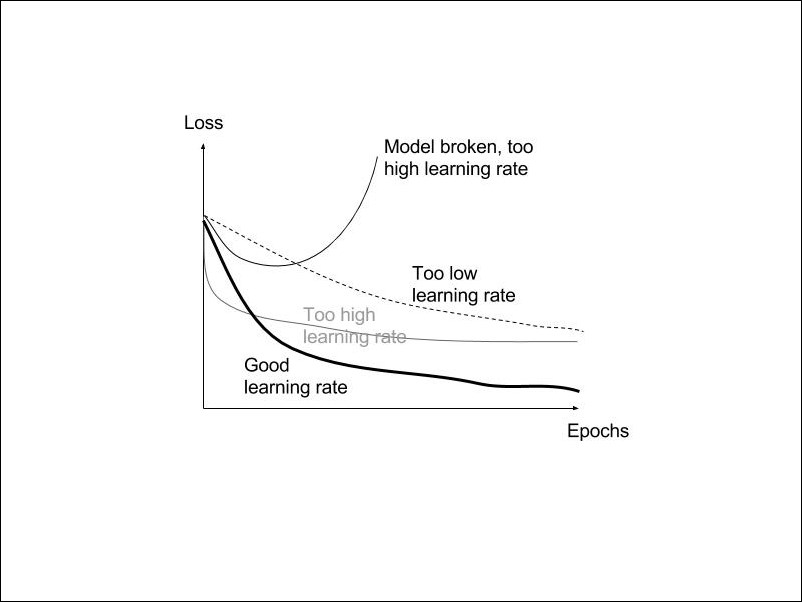
When training loss does not improve anymore for one or a few more iterations, the learning rate can be reduced by a factor:
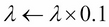
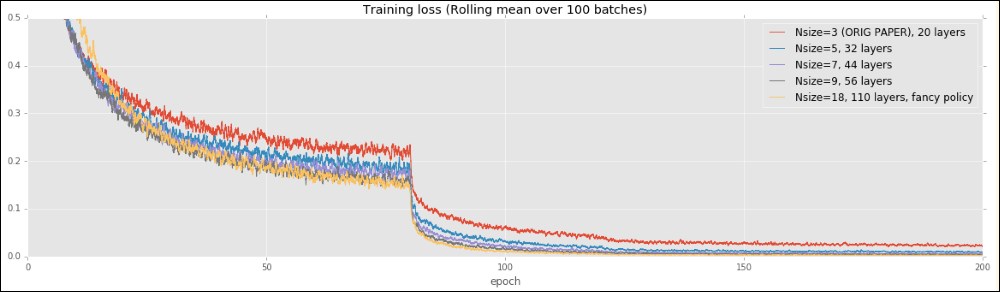
It helps the network learn fine-grained differences in the data, as shown when training residual networks (Chapter 7, Classifying Images with Residual Networks):
To check the training process, it is usual to print the norm of the parameters, the gradients, and the updates, as well as NaN values.
The update rule seen in this chapter is the simplest form of update, known as Stochastic Gradient Descent (SGD). It is a good practice to clip the norm to avoid saturation and NaN values. The updates list given to the theano...

















