























































Visualizing page relationships on Wikipedia
In this recipe we take the data we collected in the previous recipe and create a force-directed network visualization of the page relationships using the NetworkX Python library.
Getting ready
NetworkX is software for modeling, visualizing, and analyzing complex network relationships. You can find more information about it at: https://networkx.github.io. It can be installed in your Python environment using pip install networkx.
How to do it
The script for this example is in the 08/06_visualizze_wikipedia_links.py file. When run it produces a graph of the links found on the initial Python page in Wikipedia:
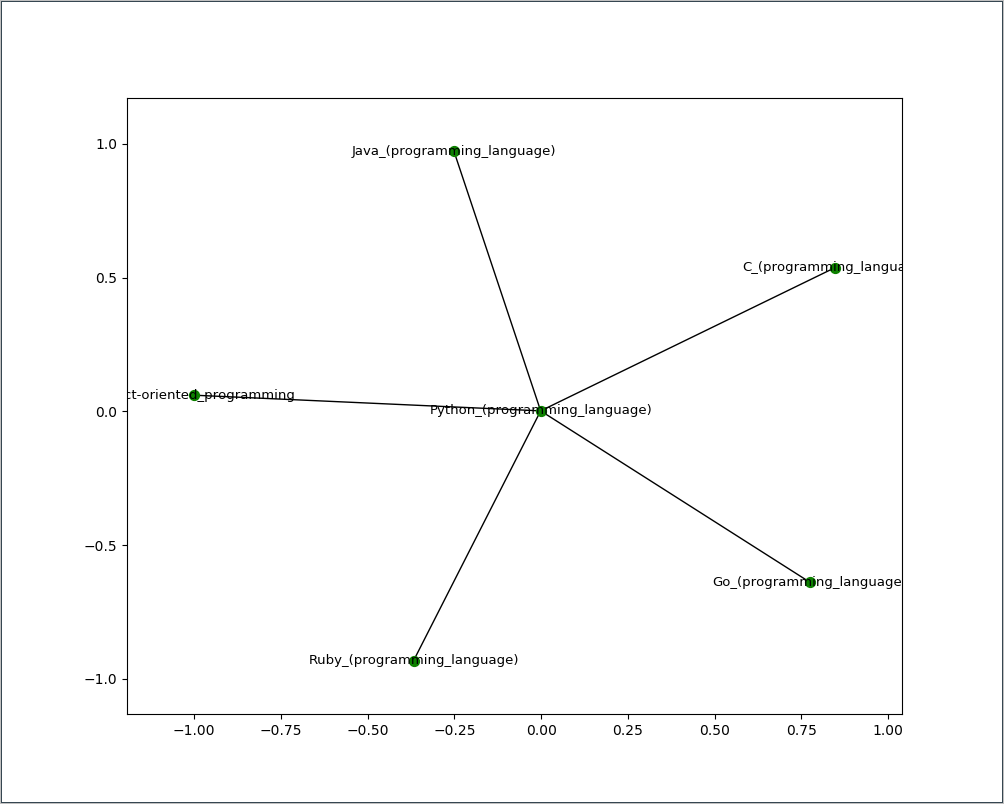
Graph of the links
Now we can see the relationships between the pages!
How it works
The crawl starts with defining a one level of depth crawl:
crawl_depth = 1
process = CrawlerProcess({
'LOG_LEVEL': 'ERROR',
'DEPTH_LIMIT': crawl_depth
})
process.crawl(WikipediaSpider)
spider = next(iter(process.crawlers)).spider
spider.max_items_per_page = 5...






