























































Processing infinitely scrolling pages
Many websites have replaced "previous/next" pagination buttons with an infinite scrolling mechanism. These websites use this technique to load more data when the user has reached the bottom of the page. Because of this, strategies for crawling by following the "next page" link fall apart.
While this would seem to be a case for using browser automation to simulate the scrolling, it's actually quite easy to figure out the web pages' Ajax requests and use those for crawling instead of the actual page. Let's look at spidyquotes.herokuapp.com/scroll as an example.
Getting ready
Open http://spidyquotes.herokuapp.com/scroll in your browser. This page will load additional content when you scroll to the bottom of the page:
Screenshot of the quotes to scrape
Once the page is open, go into your developer tools and select the network panel. Then, scroll to the bottom of the page. You will see new content in the network panel:
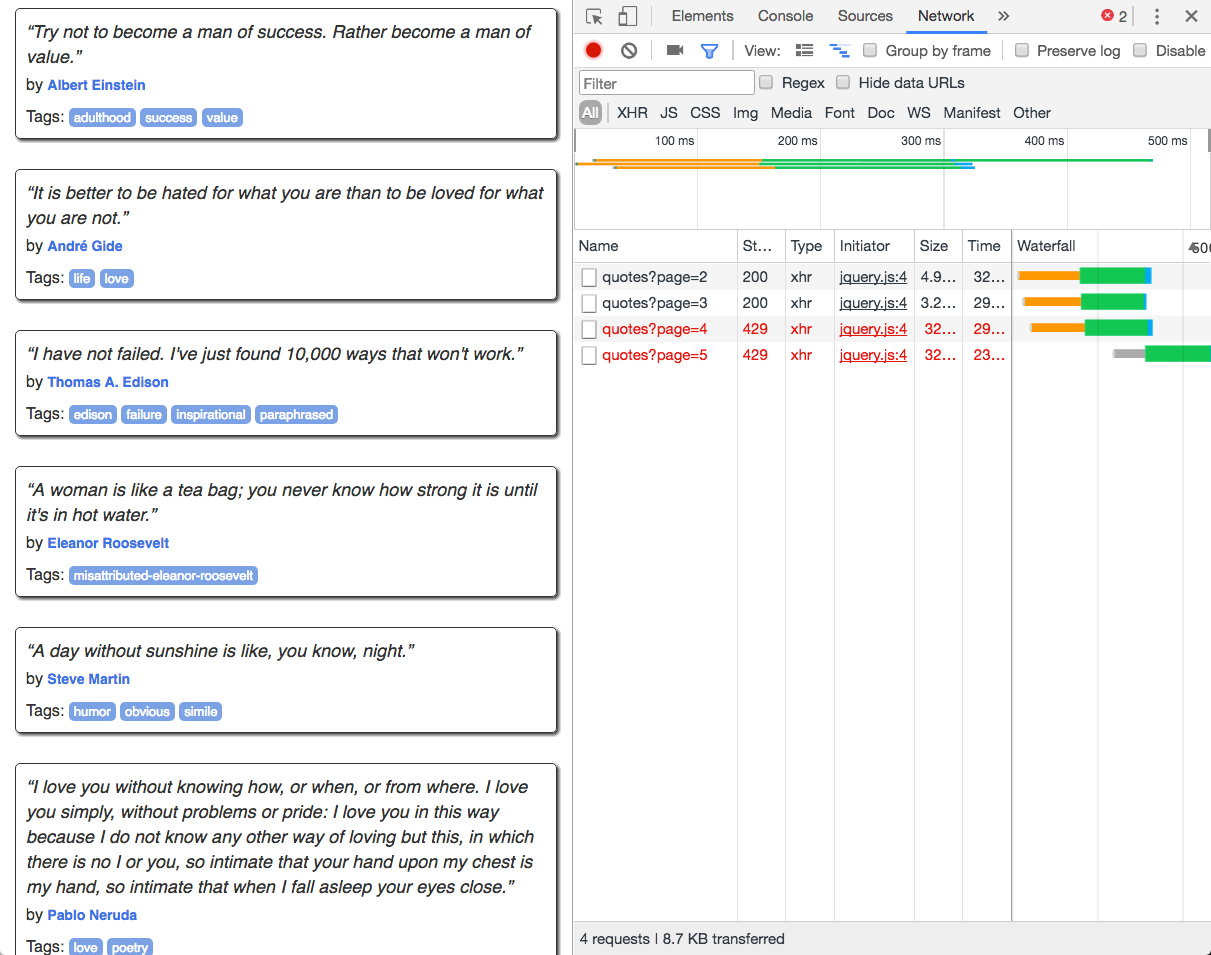
Screenshot of the developer tools options...







