























































k-Nearest Neighbors
Before we build a KNN model for the HR attrition dataset, let us understand KNN's triple W.
What is k-Nearest Neighbors?
KNN is one of the most straightforward algorithms that stores all available data points and predicts new data based on distance similarity measures such as Euclidean distance. It is an algorithm that can make predictions using the training dataset directly. However, it is much more resource intensive as it doesn't have any training phase and requires all data present in memory to predict new instances.
Note
Euclidean distance is calculated as the square root of the sum of the squared differences between two points.
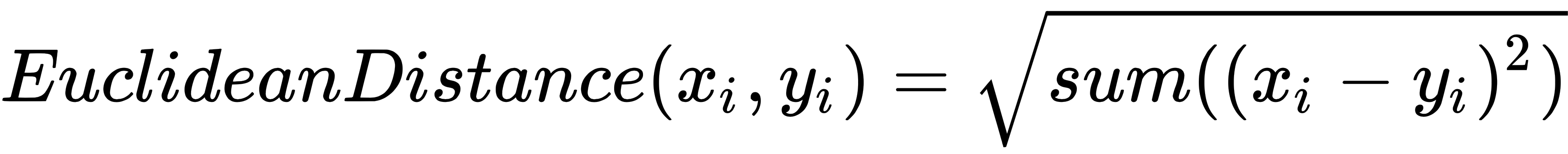
Where is KNN used?
KNN can be used for building both classification and regression models. It is applied to classification tasks, both binary and multivariate. KNN can even be used for creating recommender systems or imputing missing values. It is easy to use, easy to train, and easy to interpret the results.
















