























































The SARSA algorithm
The State–Action–Reward–State–Action (SARSA) algorithm is an on-policy learning problem. Just like Q-learning, SARSA is also a temporal difference learning problem, that is, it looks ahead at the next step in the episode to estimate future rewards. The major difference between SARSA and Q-learning is that the action having the maximum Q-value is not used to update the Q-value of the current state-action pair. Instead, the Q-value of the action as the result of the current policy, or owing to the exploration step like
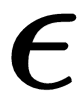
-greedy is chosen to update the Q-value of the current state-action pair. The name SARSA comes from the fact that the Q-value update is done by using a quintuple Q(s,a,r,s',a') where:
- s,a: current state and action
- r: reward observed post taking action a
- s': next state reached after taking action a
- a': action to be performed at state s'
Steps involved in the SARSA algorithm are as follows:
Initialize Q-table randomly
For each episode:
For the given state s, choose...

















