























































Making our crawler recursive
In this section, we'll start learning how to extract links, and then we'll use them to make the crawler recursive. Now that we have created the basic structure of a crawler, let's add some functionality:
- First, let's copy the prepared
spiderman.pyfile for this exercise. Copy it fromexamples/spiders/spiderman-recursive.pytobasic_crawler/basic_crawler/spiders/spiderman.py.
- Then, go back to our editor. As we would like to make the crawler recursive, for this purpose, we will once again work the
spiderman.pyfile and start with adding another extractor. However, this time we'll add the links instead of titles, as highlighted in the following screenshot:
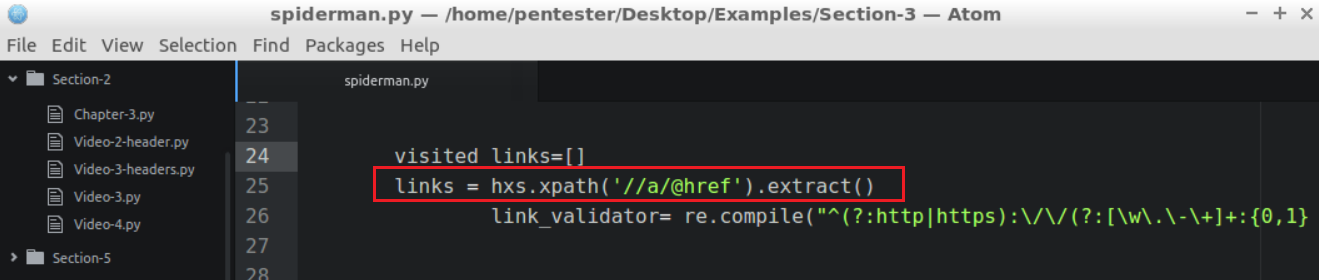
- Also, we need to make sure that the links are valid and complete, so we'll create a regular expression that will validate links highlighted in the following screenshot:
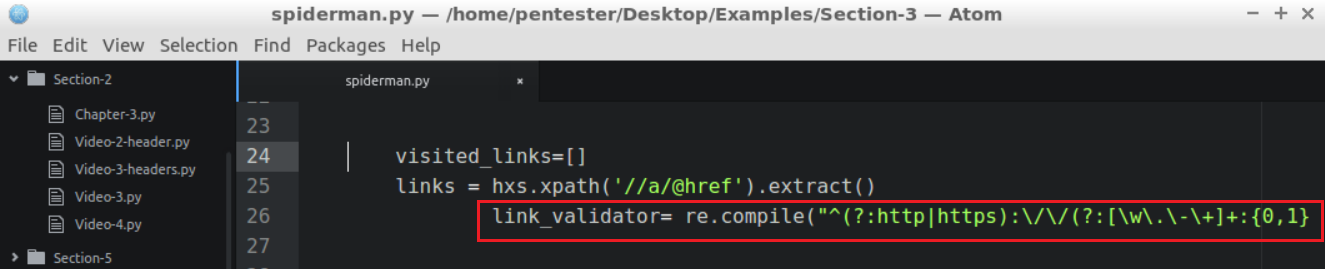
- This regular expression should validate all HTTP and HTTPS absolute links. Now that we have the code to extract the links, we need an array to control...















