























































Creating our own crawler/spider with Scrapy
In this section, we'll create our first Scrapy project. We'll define our objective, create our spider, and finally, run it and see the results.
Starting with Scrapy
First, we need to define what we want to accomplish. In this case, we want to create a crawler that will extract all the book titles from https://www.packtpub.com/. In order to do so, we need to analyze our target. If we go to the https://www.packtpub.com/ website and right-click on a book title and select Inspect, we will see the source code of that element. We can see, in this case, that the book title has this format:
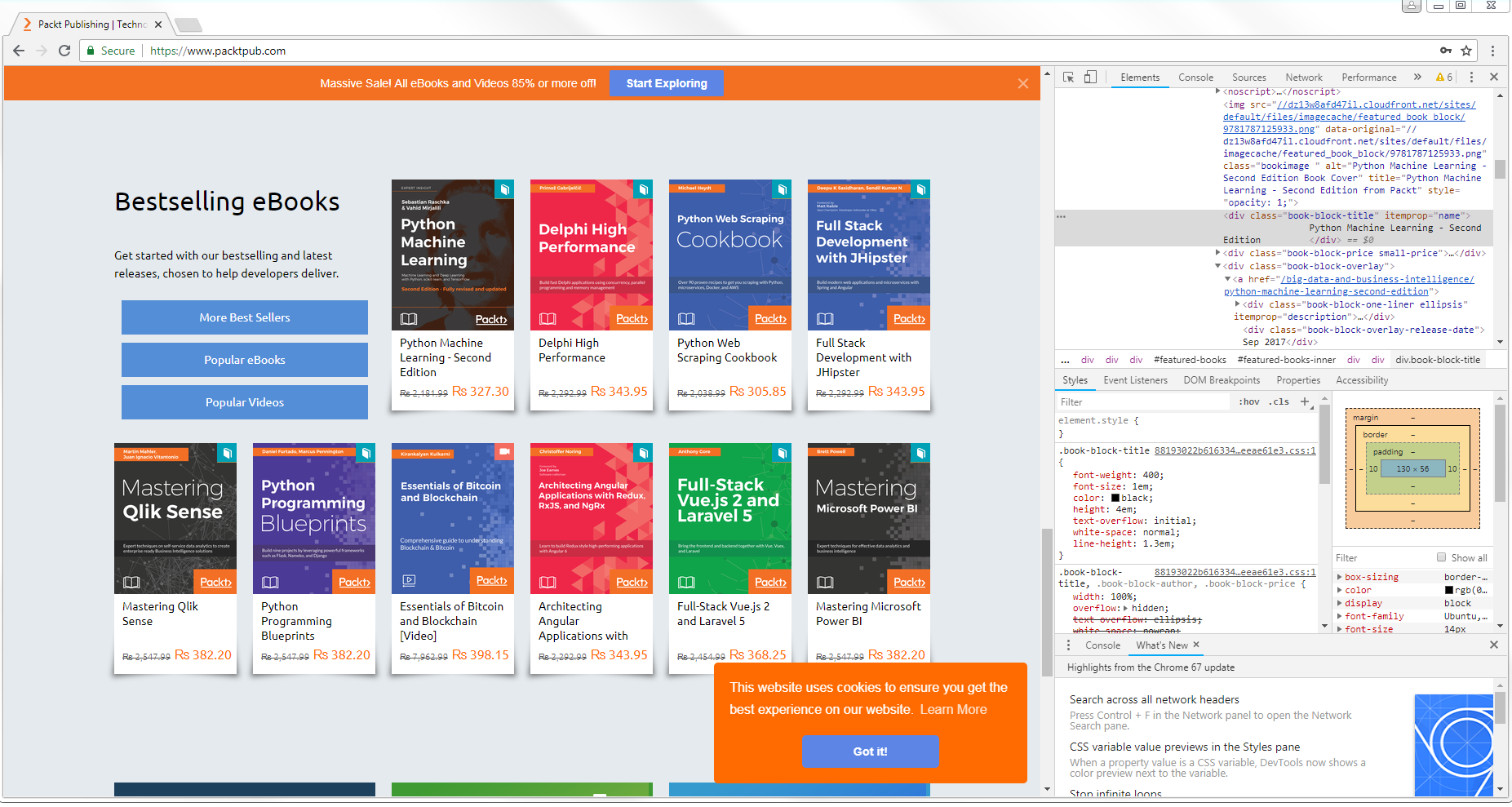
Creating a crawler for extracting all the book titles
Here, we can see div with a class of book-block-title, and then the title name. Keep this in mind or in a notebook, as that would be even better. We need this to define what we want to extract in our crawl process. Now, let's get coding:
- Let's go back to our virtual machine and open a Terminal. In order to create a crawler...















