























































Sizing up your executors
When you set up Spark, executors are run on the nodes in the cluster. To put it simply, executors are the processes where you:
- Run your compute
- Store your data
Each application has its own executor processes and they will stay up and running until your application is up and running. So by definition, they seem to be quite important from a performance perspective, and hence the three key metrics during a Spark deployment are:
- --num-executors: How many executors you need?
- --executor-cores: How many CPU cores would you want to allocate to each executor?
- --executor-memory: How much memory will you like to assign to each executor process?
So how do you allocate physical resources to Spark? While this may generally depend on the nature of the workload, you can vary between the following extreme parameters.

Figure 11.2: Executor granularity
Extreme approaches are generally a bad option except for very specific workload situations. For example, if you define very small sized executors for example, 1 core/executor or 4GB/executor you will not be able to execute multiple tasks within the same executor and hence will not benefit from cache sharing.
Similarly, in other cases where you have extremely large executors for example, on a 16-core machine having a 16-core executor with the maximum amount of RAM possible (e.g. 128 GB). This will obviously mean you won't have any space for anything else to run on that machine which can include OS and other daemons. Even if you leave space for other daemons, this is still not a good way to size your machine. while Spark-on-YARN can dynamically help you configure the number of executors, it still can't help you with the number of cores per executor and the memory to be allocated.
So how do you configure your cluster?
Calculating memory overhead
We are going to assume you are using YARN. However, this will hold true for other cluster managers too. The hierarchy of memory properties of Spark and YARN is shown in the following screenshot (Reference: http://bit.ly/2lUQUEQ).
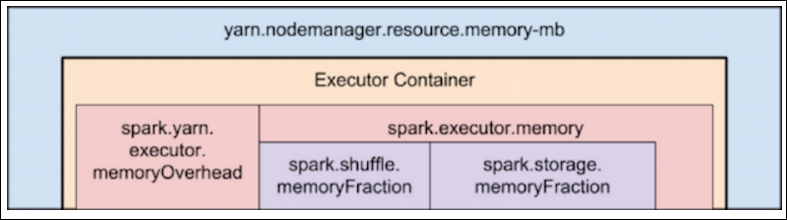
Figure 11.3: Memory hierarchy - Spark on YARN
You will need to allocate memory for the executor overhead, which typically includes VM overhead, internalized string: (http://bit.ly/2lUQ2Ad) and so on. The Spark.yarn.executor.memoryOverhead property controls the amount of off-heap memory to be allocated for each Executor. This can either be a minimum of 384 MB or 10% of your executor memory (whichever is larger). So let's assume you have 128 GB of RAM per node, and you ask for 128 GB from YARN Resource Manager, you'll actually be making a request for 140.8 GB (128 * 1.10 = 140.8 GB). This is actually more than the memory available on the node. So a better way to deal with this is to request at least 10% lesser memory, so that after the addition of overhead, you still do not exceed the total memory on the node.
Setting aside memory/CPU for YARN application master
As we have seen earlier you can run Spark in either a client deployment mode or a cluster deployment mode. In the cluster deployment mode, your driver program will run as a part of the YARN Application Master, which means one core assigned to the AM. You will need to make sure you allocate this properly. Hence if you have a 5 node cluster with 16 core /128 GB RAM per node, you need to figure out the number of executors; then for the memory per executor make sure you take into account the system over head.
I/O throughput
In the case of having a least granular executor, where you allocate all the cores to the executor, you will suffer by not getting adequate I/O throughput. If you are using HDFS, most practitioners (including Cloudera's official documentation) recommend a maximum of 5 tasks per executor, which should be the number of cores you allocate to your executor.
Sample calculations
Let us take a look at the following sample calculations:
- 5 node cluster
- 128 GB RAM / Node
- 16 cores per node
- Total cores Available= 16 * 5 = 80
- Total cores Usable (1 core for OS) = 15 * 5 = 75
- Total RAM available per node = 128 GB
We leave out 2 GB RAM per Node for OS, leaving us with 126 GB of RAM to work with.
Typical configuration:
- --executor-cores: Based on the 5 cores per executor, we can have a maximum of 15 executors and 3 executors per node (75/5=15)
- --executor-memory: For the RAM allocation, we will allocate 126/3=41 GB RAM per executor
- --num-executors: Since we have to leave out one executor for AM, we will have only 14 total executors (15 - 1 = 14)
Please do understand that while these are typical configurations, your configuration might change based on your cluster configuration and your typical workload. You need to see if your applications are making full use of the resources, and if not you can always reconfigure based on the feedback that you receive from your cluster.

















