























































Security configuration in Spark
Spark currently supports two methods of authentication:
- Kerberos
- Shared Secret
Kerberos authentication
It is recommended to use Kerberos authentication when using Spark on YARN.
A Kerberos Principal is used in a Kerborized system to represent a unique identity. Kerberos can assign tickets to these identities, which helps them identify themselves while accessing Hadoop clusters secured by Kerberos. While the principals can generally have an arbitrary number of components, in Hadoop the principals are of the following format: username/[email protected]. Your user name here can refer to an existing account like HDFS, Mapred, or Spark.
You will need to follow the following steps:
Creation of the Spark Principal and Keytab file - You will need to create a Spark Principal and the Spark keytab file using the following commands:
Tip
FQDN is your Full Qualified Domain Name
- Creating the Principal:
kadmin: addprinc -randkey spark/[email protected]- Creating the Keytab file:
kadmin: xst - spark.keytab spark/fqdn- Relocating the keytab file to the Spark configuration directory:
mv spark.keytab /etc/spark/conf- Securing the Keytab file:
chown spark /etc/spark/conf/spark.keytab chmod 400 /etc/spark/conf/spark.keytab
Add Principal and Keytab properties to the spark-env.sh file - You have to configure the Spark history server to use Kerberos, and this can be done by specifying the Principal and Keytab created above in the Spark-env.sh file. The Spark-env.sh file is typically located in the conf directory.
vi /etc/spark/conf/spark-env.sh SPARK_HISTORY_OPTS=-Dspark.history.kerberos.enabled=true \ -Dspark.history.kerberos.principal=spark/FQDN@REALM \ -Dspark.history.kerberos.keytab=/etc/spark/conf/spark.keytab
Kerberos options for Spark-submit - When you are submitting applications using Spark-submit, you have the following options available for use on a secure cluster:
- --proxy-user
- --principal
- --keytab
The help system for these commands will give you a fairly good idea of what these are used for:
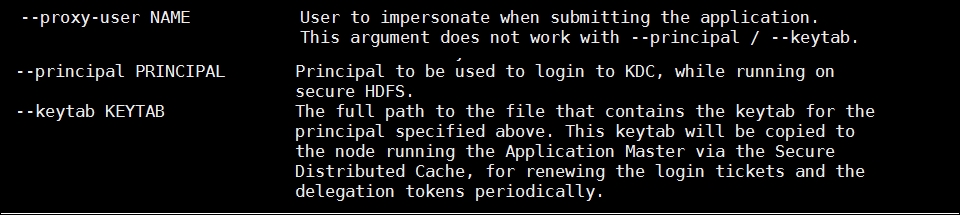
Figure 11.5: Kerberos related options in Spark-Submit
A keytab is a file that consists of your Kerberos prinicpals and your encrypted keys. A keytab file is used to authenticate a Kerberos principal on a host to Kerberos without human interaction or storing a password in a plain text file. If you have access to a keytab file, you can act as the principal whose credentials are secured in the keytab file, which makes them an asset of high importance and hence creates a greater need for them to be secured.
Shared secrets
Spark supports authentication via shared secret. The parameter used to configure the authentication is spark.authenticate, which controls the authentication via shared secret. The authentication process is quite simply a handshake between Spark and the other party to ensure that they have the same shared secret and can be allowed to communicate.
Shared secret on YARN
Configuring spark.authenticate to true will automatically handle generating and distributing shared secret. Each application will use a unique shared secret.
Shared secret on other cluster managers
For other types of Spark deployment, spark.authenticate.secret should be configured on each of the nodes. This secret will be used by all the Master/Workers and applications.
You can read more about shared secrets on the Apache Spark documentation pages (http://bit.ly/2kyWkZo).

















