Deep learning is a subset of machine learning, which is a field of artificial intelligence that uses mathematics and computers to learn from data and map it from some input to some output. Loosely speaking, a map or a model is a function with parameters that maps the input to an output. Learning the map, also known as mode, occurs by updating the parameters of the map such that some expected empirical loss is minimized. The empirical loss is a measure of distance between the values predicted by the model and the target values given the empirical data.
Notice that this learning setup is extremely powerful because it does not require having an explicit understanding of the rules that define the map. An interesting aspect of this setup is that it does not guarantee that you will learn the exact map that maps the input to the output, but some other maps, as expected, predict the correct output.
This learning setup, however, does not come without a price: some deep learning methods require large amounts of data, specially when compared with methods that rely on feature engineering. Fortunately, there is a large availability of free data, specially unlabeled, in many domains.
Meanwhile, the term deep learning refers to the use of multiple layers in an ANN to form a deep chain of functions. The term ANN suggests that such models informally draw inspiration from theoretical models of how learning could happen in the brain. ANNs, also referred to as deep neural networks, are the main class of models considered in this book.
Despite its recent success in many applications, deep learning is not new and according to Ian Goodfellow, Yoshua Bengio, and Aaron Courville, there have been three eras:
- Cybernetics between the 1940s and the 1960s
- Connectionism between the 1980s and the 1990s
- The current deep learning renaissance beginning in 2006
Mathematically speaking, a neural network is a graph consisting of non-linear equations whose parameters can be estimated using methods such as stochastic gradient descent and backpropagation. We will introduce ANNs step by step, starting with linear and logistic regression.
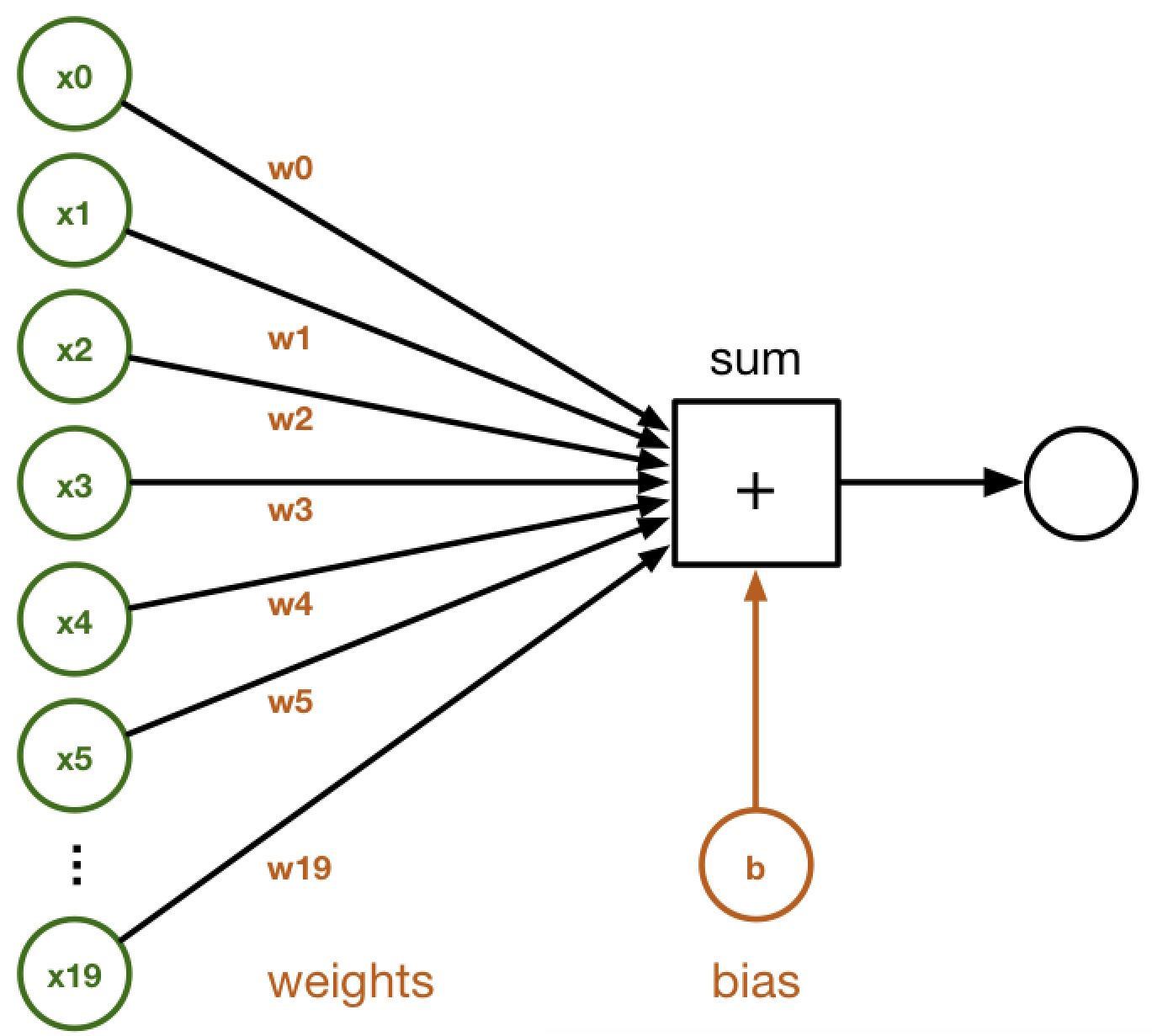
Linear regression is used to estimate the parameters of a model to describe the relationship between an output variable and the given input variables. It can be mathematically described as a weighted sum of input variables:
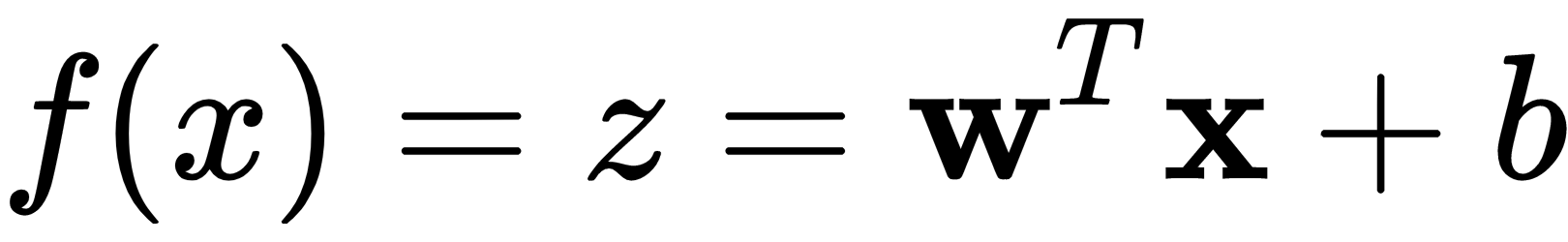
Here, the weight, 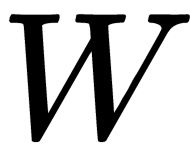 , and inputs,
, and inputs, 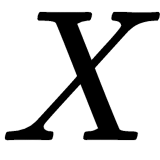 , are vectors in
, are vectors in 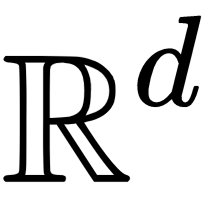 ; in other words, they are real-valued vectors with
; in other words, they are real-valued vectors with 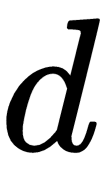 dimensions,
dimensions, 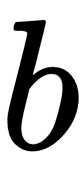 as a scalar bias term, and
as a scalar bias term, and  as a scalar term that represents the valuation of the
as a scalar term that represents the valuation of the 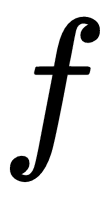 function at the input
function at the input 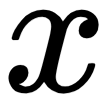 . In ANNs, the output of a single neuron without non-linearities is similar to the output of the linear model described in the preceding linear regression equation and the following diagram:
. In ANNs, the output of a single neuron without non-linearities is similar to the output of the linear model described in the preceding linear regression equation and the following diagram:
Logistic regression is a special version of regression where a specific non-linear function, the sigmoid function, is applied to the output of the linear model in the earlier linear regression equation:
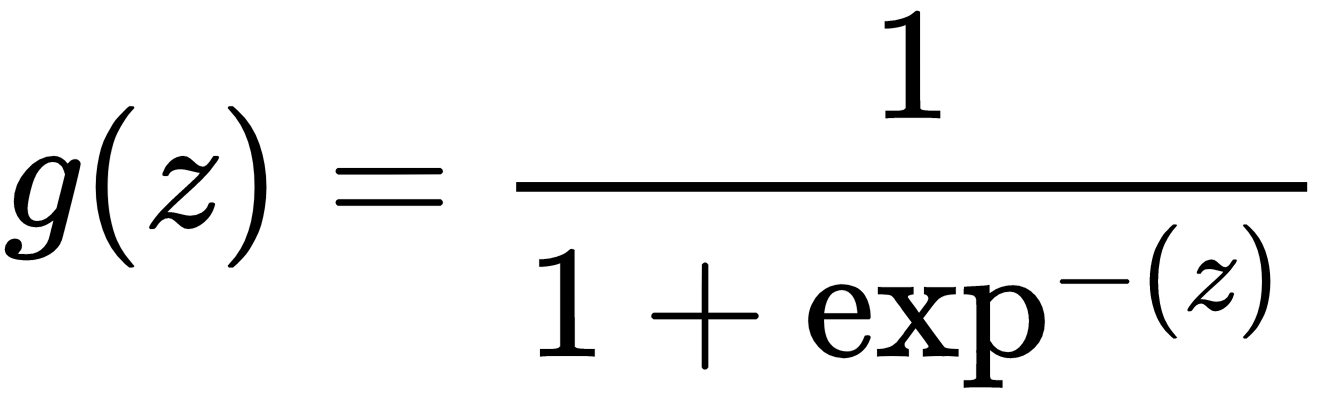
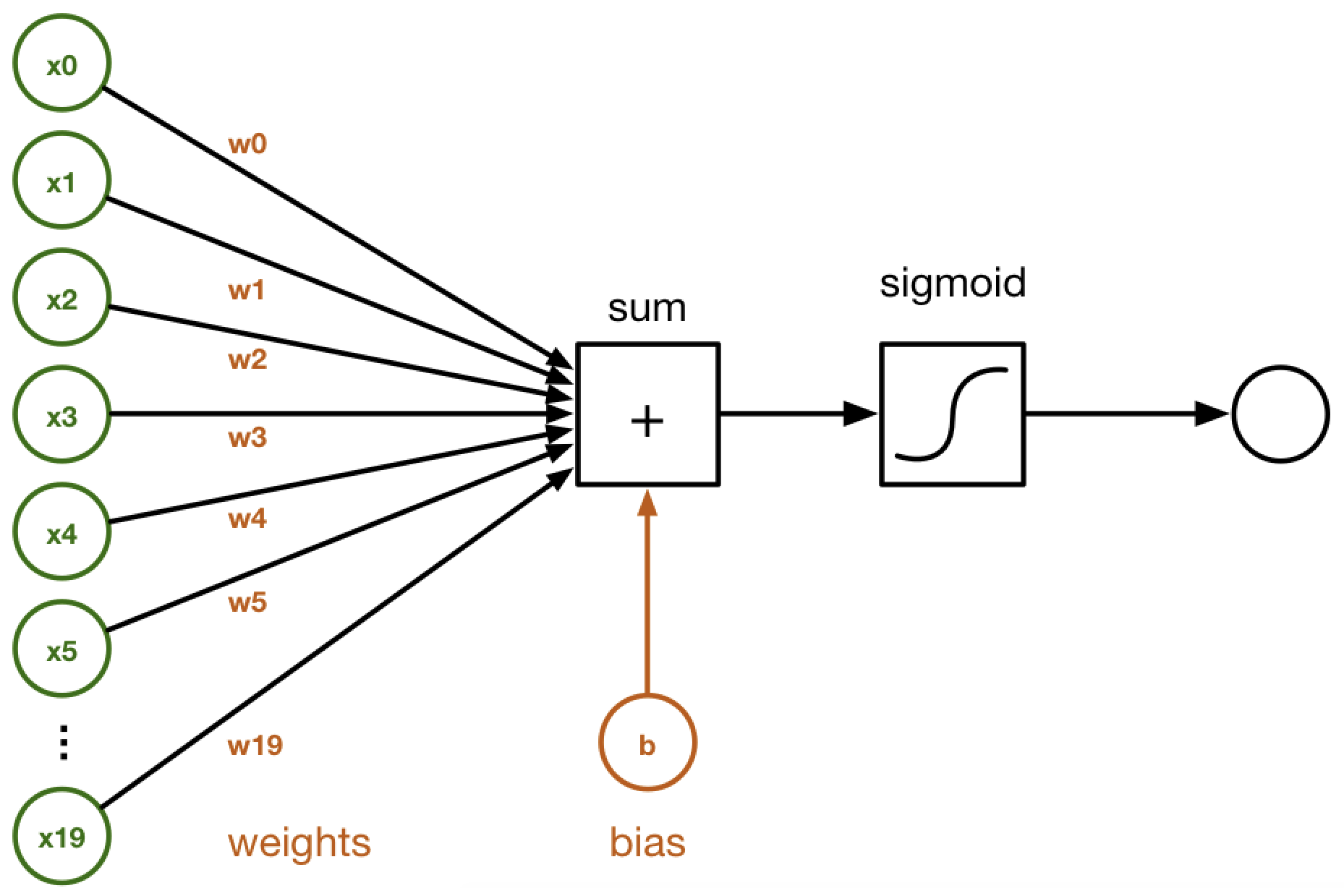
The In ANNs, the non-linear model described in the logistic regression equation is similar to the output of a single neuron with a sigmoid non-linearity in the following diagram:
A combination of such neurons defines a hidden layer in a neural network, and the neural networks are organized as a chain of layers. The output of a hidden layer is described by the following equation and diagram:
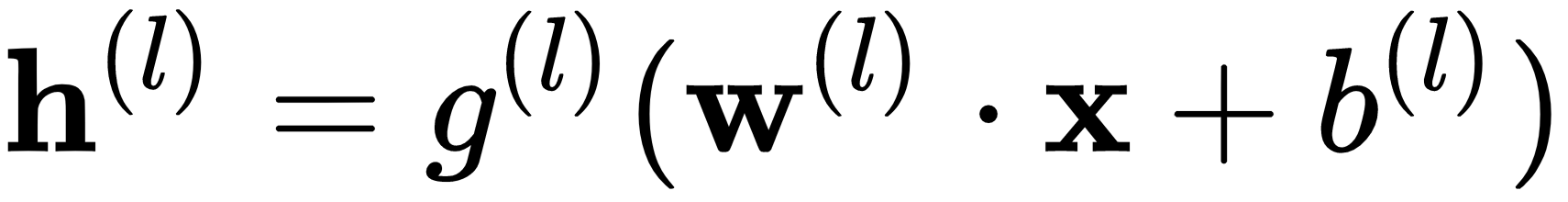
Here, the weight, 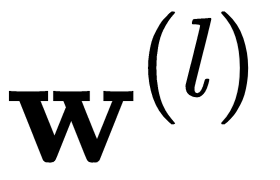 , and the input,
, and the input,  , are vectors in
, are vectors in 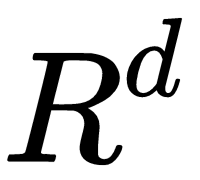 ;
; 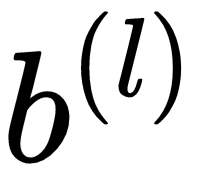 is a scalar bias term,
is a scalar bias term, 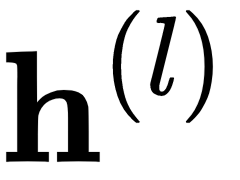 is a vector, and
is a vector, and  is a non-linearity:
is a non-linearity:
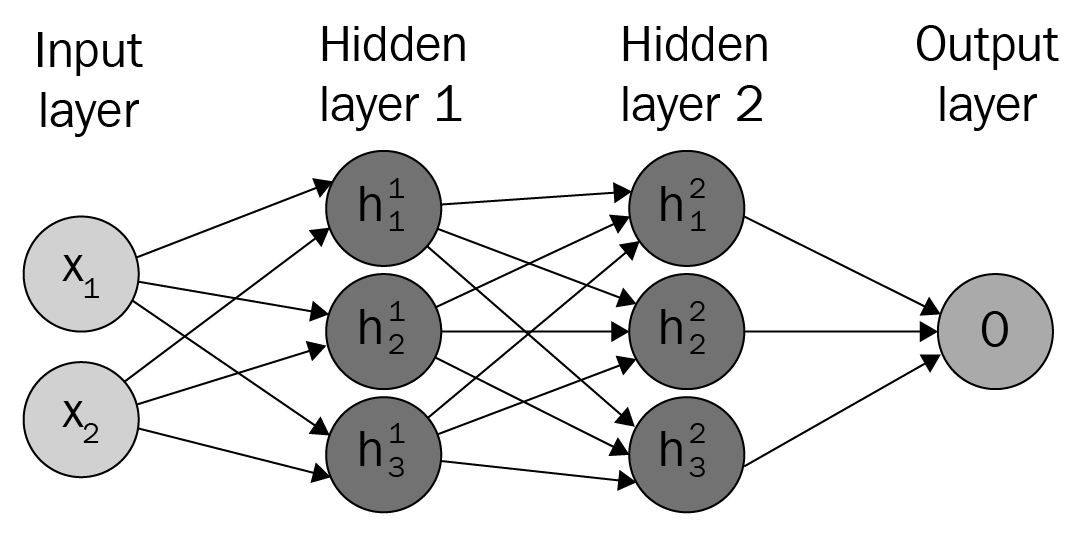
The preceding diagram depicts a fully connected neural network with two inputs, two hidden layers with three nodes each, and one output node.
In general, neural networks have a chain-like structure that is easy to visualize in equation form or as a graph, as the previous diagram confirms. For example, consider the 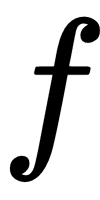 and
and  functions that are used in the
functions that are used in the 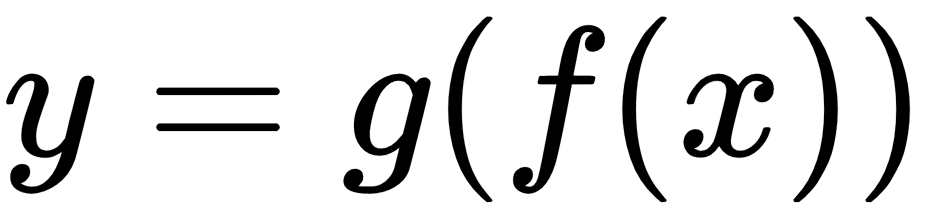 model. In this simple model of a neural network, the input
model. In this simple model of a neural network, the input 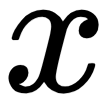 is used to produce the output
is used to produce the output 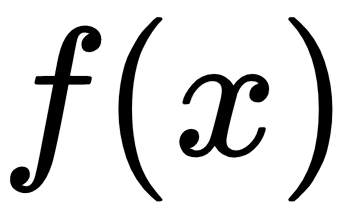 ; the output of
; the output of 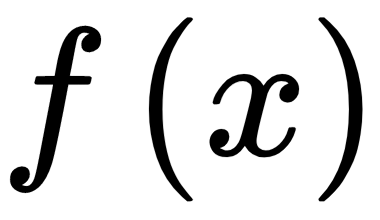 is used as the input of
is used as the input of 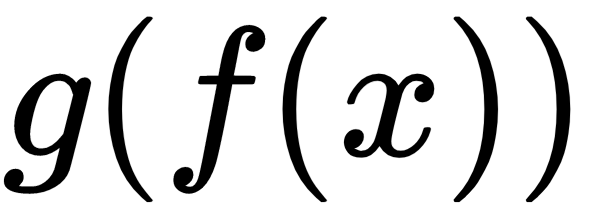 that finally produces
that finally produces 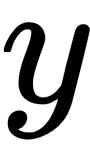 .
.
In this simple model, the function 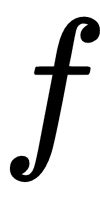 is considered to be the first hidden layer and the function
is considered to be the first hidden layer and the function  is considered to be the second hidden layer. These layers are called hidden because, unlike the input and the output values of the model that are known a priori, their values are not known.
is considered to be the second hidden layer. These layers are called hidden because, unlike the input and the output values of the model that are known a priori, their values are not known.
In each layer, the network is learning features or projections of the data that are useful for the task at hand. For example, in computer vision, there is evidence that the layers of the network closer to the input can learn filters that are associated with basic shapes, whereas in the layers closer to the output the network might learn filters that are closer to images.
The following figure taken from the paper Visualizing and Understanding Convolutional Networks by Zeiler et Fergus, provides a visualization of the filters on the first convolution layer of a trained AlexNet:

For a thorough introduction to the topic of neural network visualization, refer to Stanford's class on
Convolutional Networks for Visual Recognition.
The output of each layer on the network is dependent on the parameters of the model estimated by training the neural network to minimize the loss with respect to the weights, 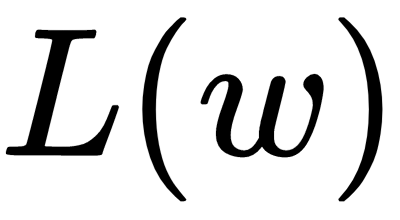 , as we described earlier. This is a general principle in machine learning, in which a learning procedure, for example backpropagation, uses the gradients of the error of a model to update its parameters to minimize the error. Consider estimating the parameters of a linear regression model such that the output of the model minimizes the mean squared error (MSE). Mathematically speaking, the point-wise error between the
, as we described earlier. This is a general principle in machine learning, in which a learning procedure, for example backpropagation, uses the gradients of the error of a model to update its parameters to minimize the error. Consider estimating the parameters of a linear regression model such that the output of the model minimizes the mean squared error (MSE). Mathematically speaking, the point-wise error between the 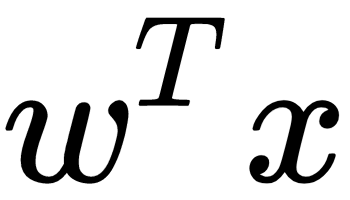 predictions and the
predictions and the 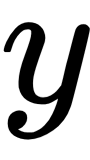 target value is computed as follows:
target value is computed as follows:
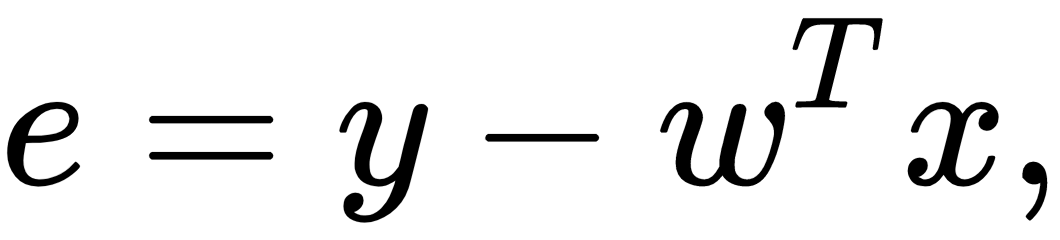
The MSE is computed as follows:
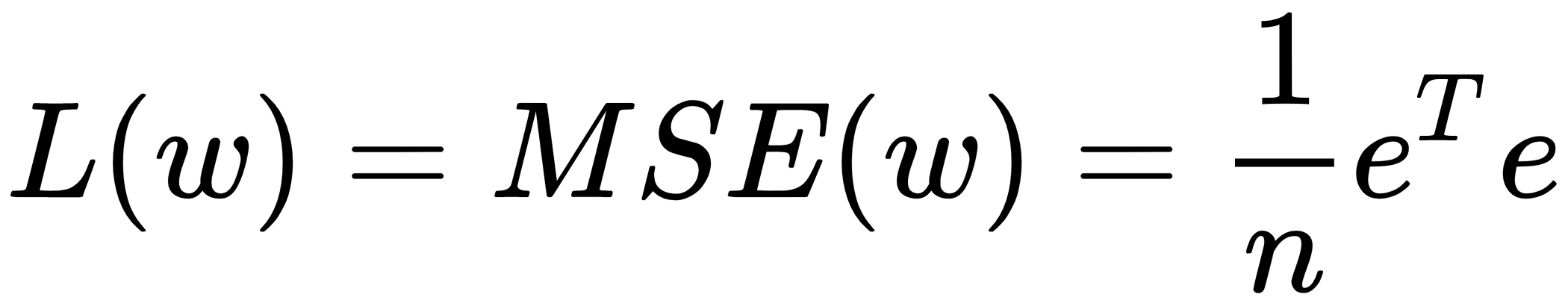 ,
,
where 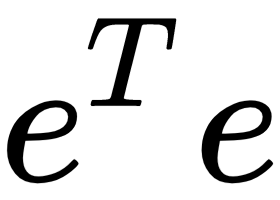 presents the sum of the squared errors (SSE) and
presents the sum of the squared errors (SSE) and 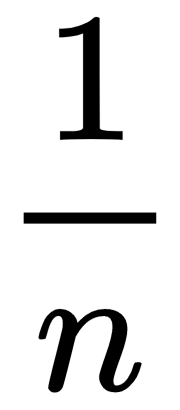 normalizes the SSE with the number of samples to reach the mean squared error (MSE).
normalizes the SSE with the number of samples to reach the mean squared error (MSE).
In the case of linear regression, the problem is convex and the MSE has the simple closed solution given in the following equation:
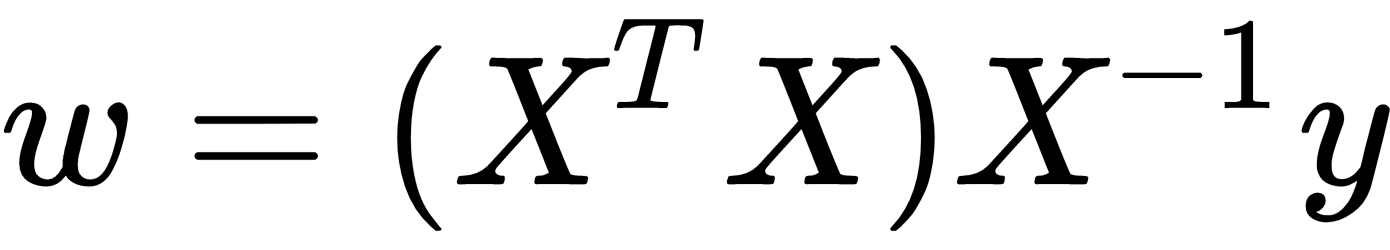
Here,  is the coefficient of the linear model,
is the coefficient of the linear model, 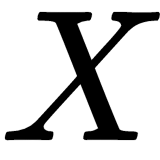 refers to matrices with the observations and their respective features, and
refers to matrices with the observations and their respective features, and 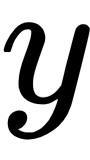 is the response value associated with each observation. Note that this closed form solution requires the
is the response value associated with each observation. Note that this closed form solution requires the 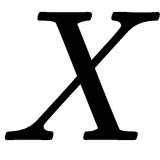 matrix to be invertible and, hence, to have a determinant larger than 0.
matrix to be invertible and, hence, to have a determinant larger than 0.
In the case of models where a closed solution to the loss does not exist, we can estimate the parameters that minimize the MSE by computing the partial derivative of each weight with respect to the MSE loss, 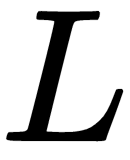 , and using the negative of that value, scaled by a learning rate,
, and using the negative of that value, scaled by a learning rate,  , to update the
, to update the  parameters of the model being evaluated:
parameters of the model being evaluated:
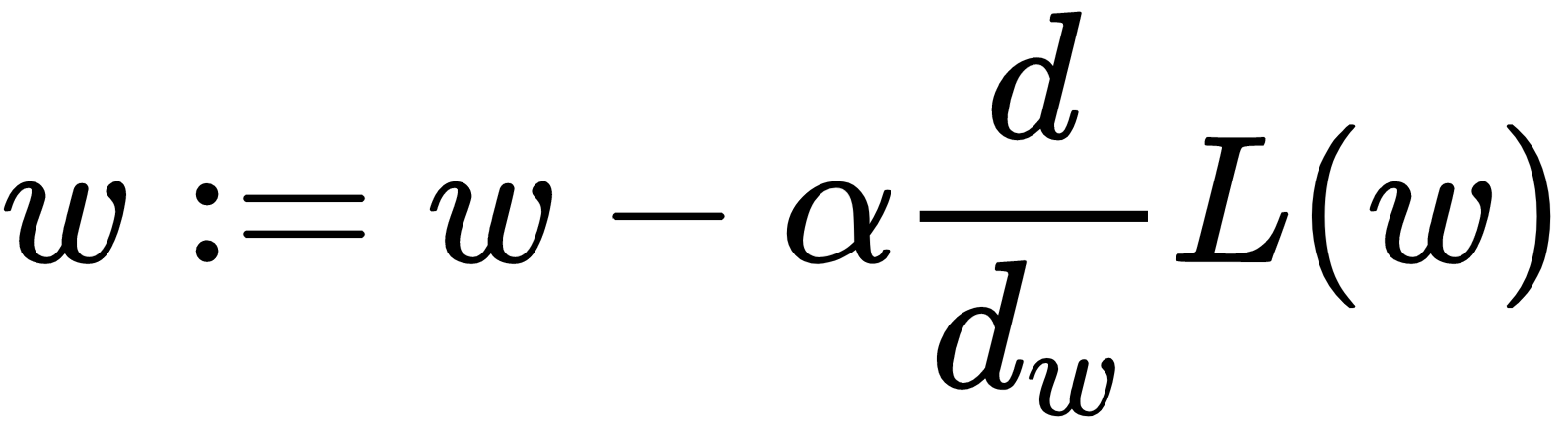
A model in which many of the coefficients in  are 0 is said to be sparse. Given the large number of parameters or coefficients in deep learning models, producing models that are sparse is valuable because it can reduce computation requirements and produce models with faster inference.
are 0 is said to be sparse. Given the large number of parameters or coefficients in deep learning models, producing models that are sparse is valuable because it can reduce computation requirements and produce models with faster inference.
The backpropagation algorithm is a special case of reverse-mode automatic differentiation. In its basic modern version, the backpropagation algorithm has become the standard for training neural networks, possibly due to its underlying simplicity and relative power.
Inspired by the work of Donal Hebb and the so-called Hebb rule, Rosenblatt developed the idea of a perceptron that was based on the formation and changes of synapses between neurons, where the output of a neuron will be modeled as a weighted sum based on its incoming signals. This weighted sum is similar to what we described in the equation(3) in this chapter.
The basic idea of backpropagation is as follows: to define an error function and reiteratively compute the gradients of the loss with respect to the model weights and perform gradient descent and weight updates that are optimal for minimizing the error function given the current data and model weights. From a perspective of calculus, backpropagation is an algorithm that efficiently computes the chain rule with a specific order of operations.
The data and the error function are extremely important factors of the learning procedure. For example, consider a classifier that is trained to identify single handwritten digits. For training the model, suppose we will use the MNIST dataset, (http://yann.lecun.com/exdb/mnist/) which is comprises 28 by 28 monochromatic images of single handwritten white digits on a black canvas, such as the ones in following figure. Ideally, we want the model to predict 1 whenever the image looks such as a 1, 2 whenever it looks such as a 2, and so on:
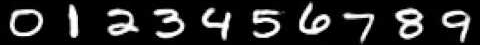
Note that backpropagation does not define what aspects of the images should be considered, nor does it provide guarantees that the classifier will not memorize the data or that it will get generalize to unseen examples. A model trained with such data will fail if the colors are inverted, for instance, black digits on a white canvas. Naturally, one way to fix this issue will be to augment the data to include images with any foreground and background color combination. This example illustrates the importance of the training data and the objective function being used.
A loss function, also known as a cost function, is a function that maps an event or values of one or more variables onto a real number intuitively representing some cost associated with the event. We will cover the following three loss functions in this chapter:
- L1 Loss
- L2 Loss
- Categorical Crossentropy Loss
The L1 loss function, also known as the mean absolute error, measures the average point-wise difference between the model prediction, 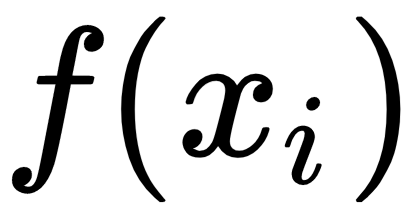 , and the target value,
, and the target value, 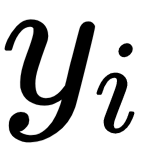 . The partial derivative is equal to 1 when the model prediction is larger than the target value, and equal to -1 when the prediction is smaller than the target error. This property of the L1 loss function can be used to circumvent problems that might arise when learning from noisy labels:
. The partial derivative is equal to 1 when the model prediction is larger than the target value, and equal to -1 when the prediction is smaller than the target error. This property of the L1 loss function can be used to circumvent problems that might arise when learning from noisy labels:
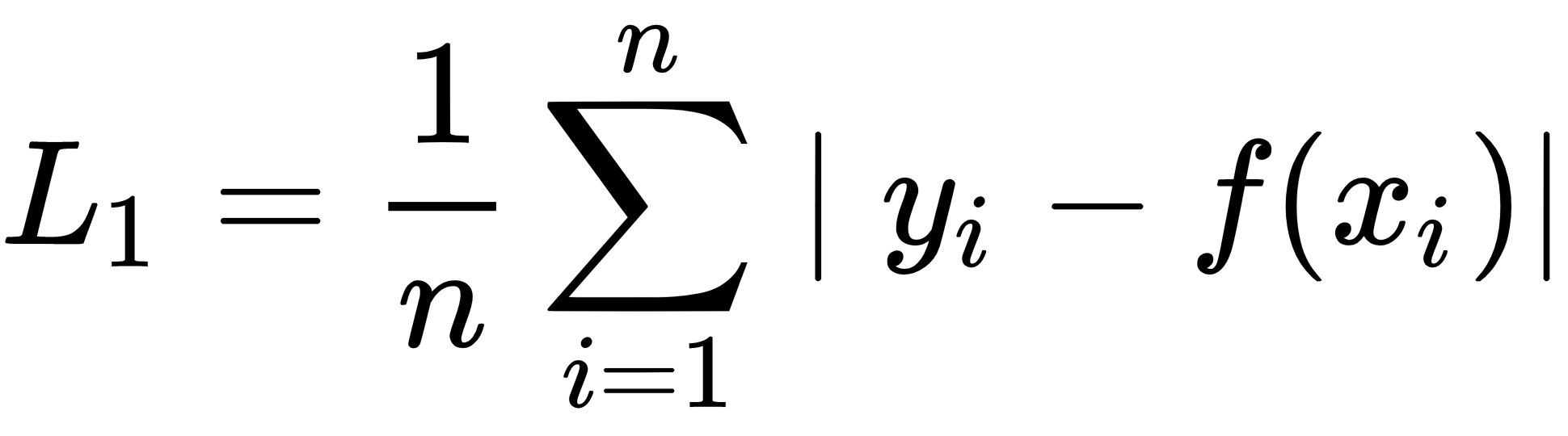
The L2 loss function, also known as MSE, measures the average point-wise squared difference between the prediction, 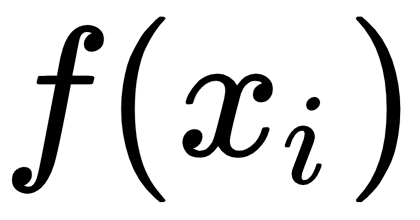 , and the target value,
, and the target value, 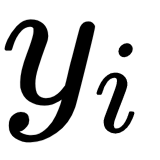 . Compared to the L1 loss function, the L2 loss function penalizes larger errors:
. Compared to the L1 loss function, the L2 loss function penalizes larger errors:
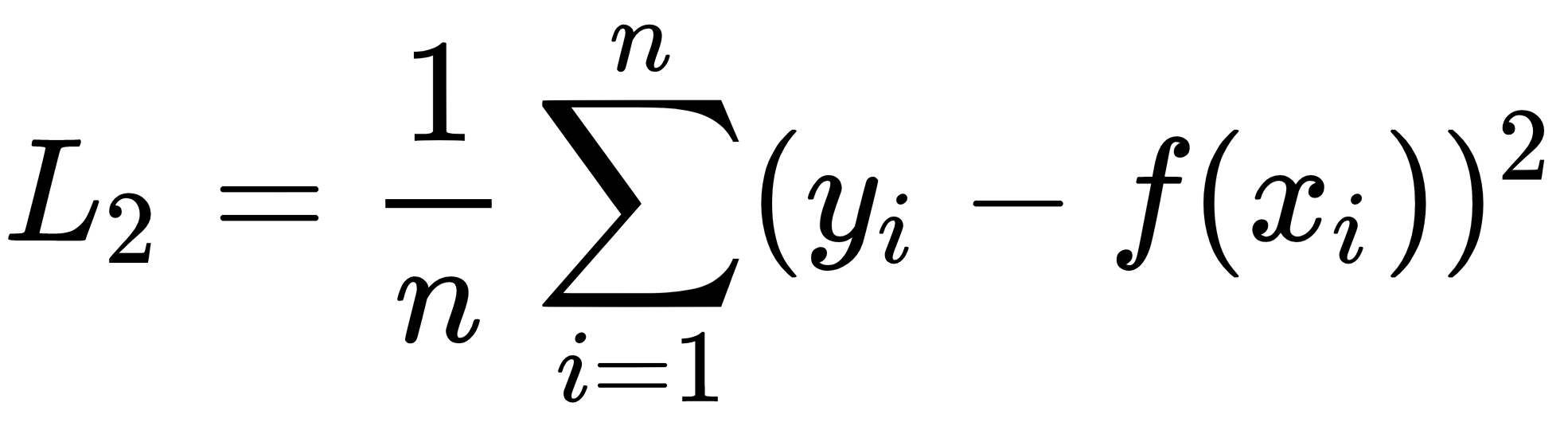
The categorical crossentropy loss function measures the weighted divergence between targets,  , and predictions,
, and predictions,  , where
, where  denotes the data point, and
denotes the data point, and 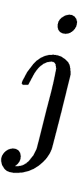 denotes the class. For single label classification problems, the
denotes the class. For single label classification problems, the 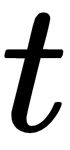 targets operate as an indicator variable and the loss is reduced to
targets operate as an indicator variable and the loss is reduced to 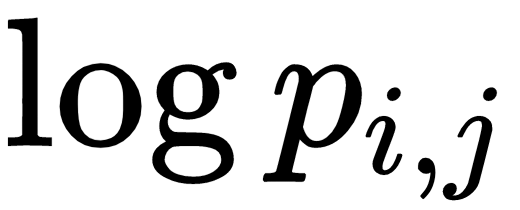 :
:
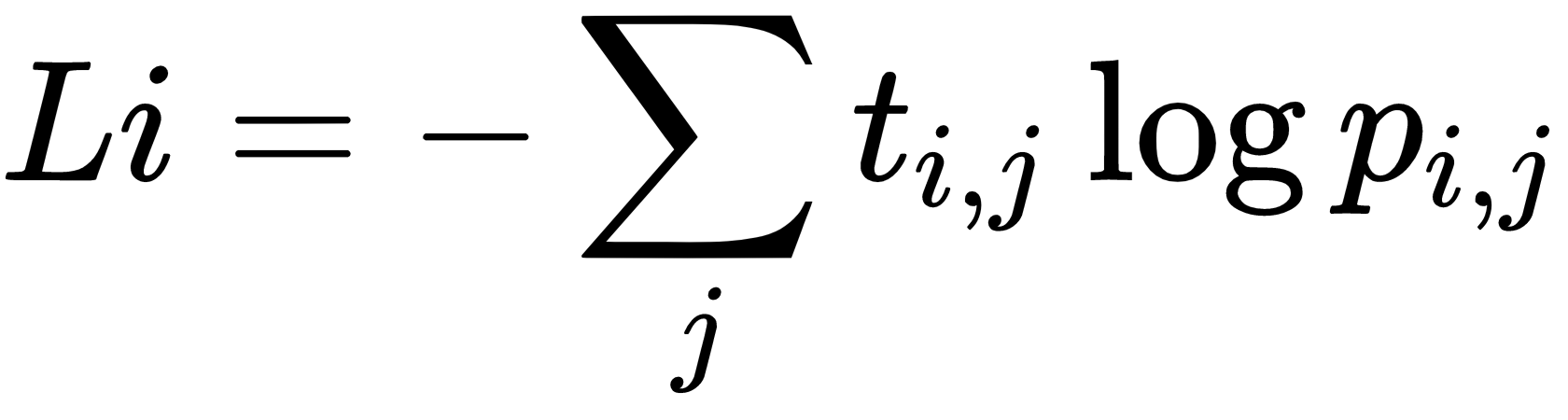
ANNs are normally non-linear models that use different types of non-linearities. The most commonly used are as follows:
The sigmoid non-linearity has an S shape and maps the input domain to an output range between [0, 1]. This characteristic of sigmoid makes it suitable for estimating probabilities, which are also in the [0, 1] range. The gradient of sigmoid is larger at its center, 0.0, and the gradients quickly vanish as the domain moves away from 0.0:
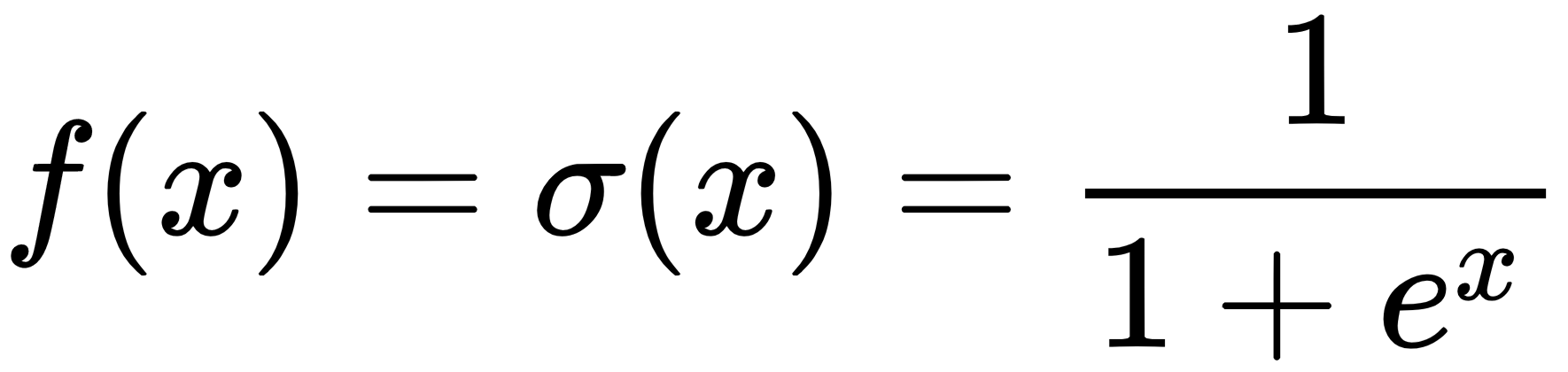
The Tanh non-linearity has an S shape that is similar to the sigmoid non-linearity, but maps the input domain to an output range between [-1, 1]. In the same way as sigmoid, the gradient of Tanh is larger at its center, 0.0, but the gradient at the center is larger for the Tanh non-linearity, hence the derivatives are steeper and the gradient is stronger:
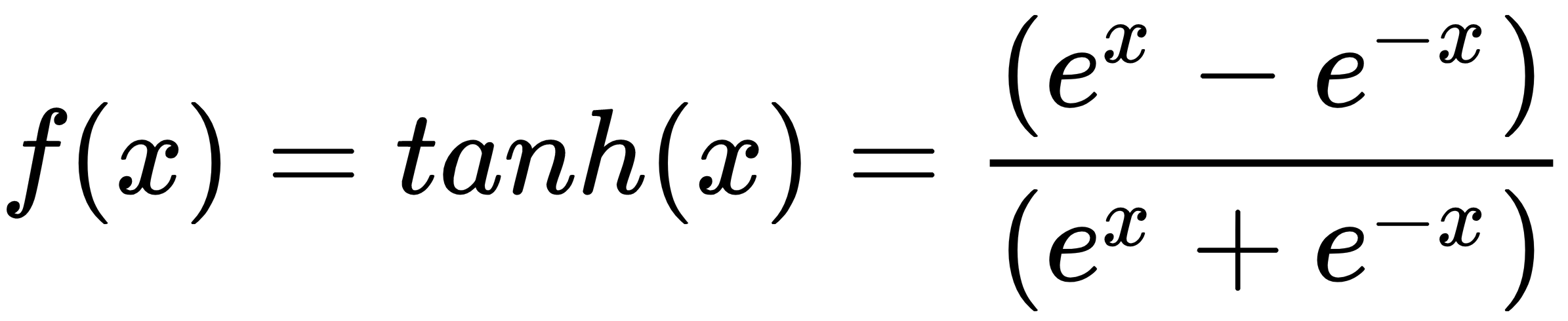
The ReLU non-linearity is a piecewise linear function with a non-linearity introduced by rectification. Unlike the sigmoid and Tanh non-linearities that have continuous gradients, the gradients of ReLU have two values only: 0 for values smaller than 0, and 1 for values larger than 0. Hence, the gradients of ReLU are sparse. Although the gradient of ReLU at 0 is undefined, common practice sets it to 0. There are variations to the ReLU non-linearity including the ELU and the Leaky RELU. Compared to sigmoid and Tanh, the derivative of ReLU is faster to compute and induces sparsity in models:
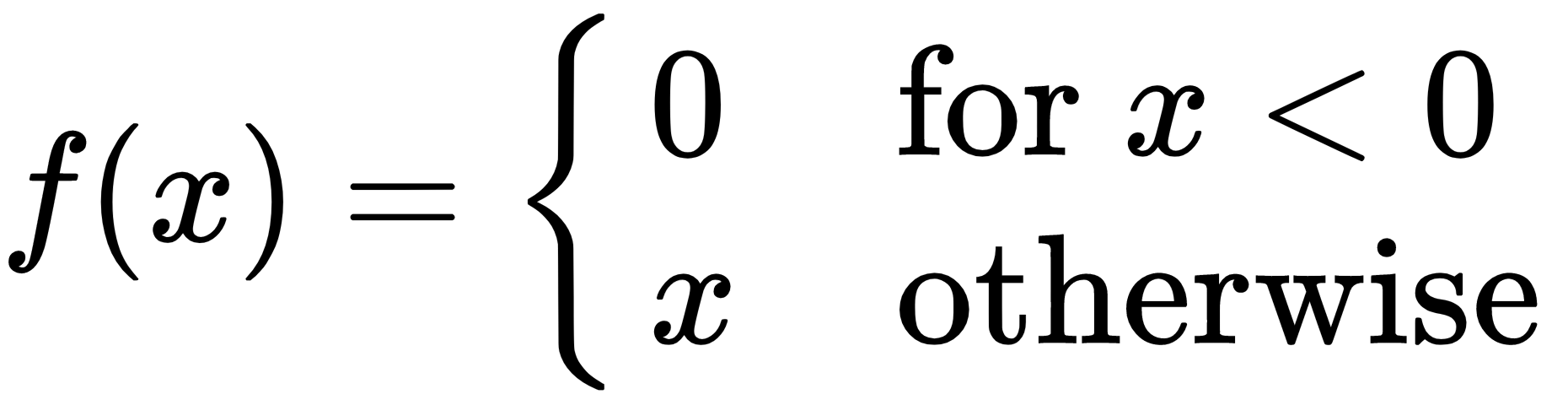
Feedforward neural networks have this name because the flow of information being evaluated by the neural network starts at the input 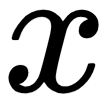 , flows all the way through the hidden layers, and finally reaches the output
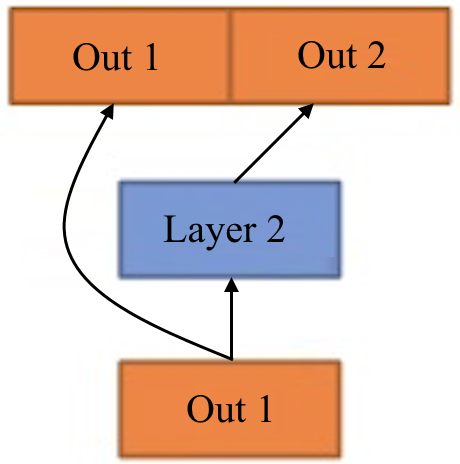
, flows all the way through the hidden layers, and finally reaches the output 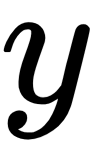 . Note that the output of each layer does flow back to itself. In some models there are residual connections in which the input of the layer is added or concatenated to the output of the layer itself. In the following figure, we provide a visualization in which the input of Layer 2, Out 1, is concatenated with the output of Layer 2:
. Note that the output of each layer does flow back to itself. In some models there are residual connections in which the input of the layer is added or concatenated to the output of the layer itself. In the following figure, we provide a visualization in which the input of Layer 2, Out 1, is concatenated with the output of Layer 2:
Convolutional Neural Networks (CNNs) are neural networks that learn filters, tensors in 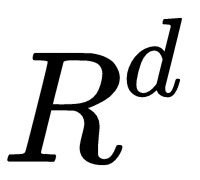 , which are convolved with the data. In the image domain, a filter is usually square and with small sizes ranging from 3 x 3 to 9 x 9 in pixel size. The convolution operation can be interpreted as sliding a filter over the data and, for each position, applying a dot product between the filter and the data at that position. The following diagram shows an intermediary step of convolution with stride 1 where the kernel in green is convolved with the first area in the data, represented by the red grid:
, which are convolved with the data. In the image domain, a filter is usually square and with small sizes ranging from 3 x 3 to 9 x 9 in pixel size. The convolution operation can be interpreted as sliding a filter over the data and, for each position, applying a dot product between the filter and the data at that position. The following diagram shows an intermediary step of convolution with stride 1 where the kernel in green is convolved with the first area in the data, represented by the red grid:
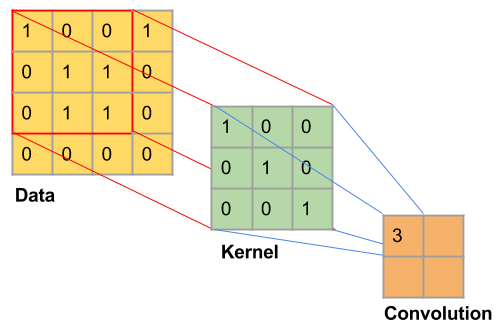
A special characteristic of CNNs is that the weights of the filters are learned. For example, if the task at hand is classifying monochromatic handwritten digits from the MNIST dataset, the ANN might learn filters that look similar to vertical, horizontal, and diagonal lines.
For more information on CNNs and convolution arithmetic, we refer the reader to the book Deep Learning by Ian Goodfellow et al., and the excellent A Guide to Convolution Arithmetic for Deep Learning by Vincent Dumoulin and Francisco Visin.
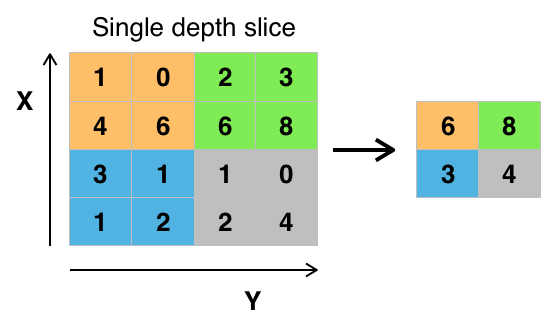
The max pooling layer is a common non-linear filter in computer vision applications. Given an 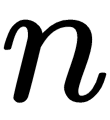 by
by 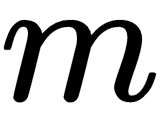 window, it consists of choosing the largest value in that window. The max pooling layers reduces the dimensionality of the data, potentially preventing overfitting and reducing computational cost. Given that within the window the max pooling layer takes the largest value in the window, disregarding spatial information, the max pooling layers can be used to learn the representations that are locally invariant to translation:
window, it consists of choosing the largest value in that window. The max pooling layers reduces the dimensionality of the data, potentially preventing overfitting and reducing computational cost. Given that within the window the max pooling layer takes the largest value in the window, disregarding spatial information, the max pooling layers can be used to learn the representations that are locally invariant to translation:

 United States
United States
 Great Britain
Great Britain
 India
India
 Germany
Germany
 France
France
 Canada
Canada
 Russia
Russia
 Spain
Spain
 Brazil
Brazil
 Australia
Australia
 South Africa
South Africa
 Thailand
Thailand
 Ukraine
Ukraine
 Switzerland
Switzerland
 Slovakia
Slovakia
 Luxembourg
Luxembourg
 Hungary
Hungary
 Romania
Romania
 Denmark
Denmark
 Ireland
Ireland
 Estonia
Estonia
 Belgium
Belgium
 Italy
Italy
 Finland
Finland
 Cyprus
Cyprus
 Lithuania
Lithuania
 Latvia
Latvia
 Malta
Malta
 Netherlands
Netherlands
 Portugal
Portugal
 Slovenia
Slovenia
 Sweden
Sweden
 Argentina
Argentina
 Colombia
Colombia
 Ecuador
Ecuador
 Indonesia
Indonesia
 Mexico
Mexico
 New Zealand
New Zealand
 Norway
Norway
 South Korea
South Korea
 Taiwan
Taiwan
 Turkey
Turkey
 Czechia
Czechia
 Austria
Austria
 Greece
Greece
 Isle of Man
Isle of Man
 Bulgaria
Bulgaria
 Japan
Japan
 Philippines
Philippines
 Poland
Poland
 Singapore
Singapore
 Egypt
Egypt
 Chile
Chile
 Malaysia
Malaysia




















