We are going to verify our deep learning environment installation by building and training a simple fully-connected neural network to perform classification on images of handwritten digits from the MNIST dataset. MNIST is an introductory dataset that contains 70,000 images, thus enabling us to quickly train a small model on a CPU and extremely fast on the GPU. In this simple example, we are only interested in testing our deep learning setup.
We start by using the keras built-in function to download and load the train and test datasets associated with MNIST:
import numpy as np
from keras.datasets import mnist
from keras.models import Sequential
from keras.utils import np_utils
from keras.optimizers import SGD
from keras.layers.core import Dense,Activation
The training set has 60,000 samples and the test set has 10,000 samples. The dataset is balanced and shuffled, that is, it has a similar number of samples for each class and the orders of the samples are random:
(X_train, y_train), (X_test, y_test) = mnist.load_data()
print("Train samples {}, Train labels {}".format(X_train.shape, y_train.shape))
print("Test samples {}, Test labels {}".format(X_test.shape, y_test.shape))
The MNIST dataset contains images of 28 by 28. To train our dense neural network, we need to combine the height and width dimensions of the image to make it unidimensional, while keeping the same batch size, that is, the number of items in the batch. After reshaping the data, we will convert it to floating point and scale it to [-1, 1] following neural networks tricks of the trade described in Yann Lecun's Efficient Backprop paper:
# reshape to batch size by height * width
h, w = X_train.shape[1:]
X_train = X_train.reshape(X_train.shape[0], h * w)
X_test = X_test.reshape(X_test.shape[0], h * w)
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
# scale to [0, 1], scale to [0, 2], offset by -1
X_train = (X_train / 255.0) * 2 - 1
X_test = (X_test - 255.0) * 2 - 1
For training our network, Keras requires each of our image labels to be in the one-hot representation. In the one-hot representation, we have a vector whose length is equal to the number of classes in which the index that represented the class associated with that label is 1, and 0 otherwise:
# convert class vectors to a matrix of one-hot vectors
n_classes = 10
y_train = np_utils.to_categorical(y_train, n_classes)
y_test = np_utils.to_categorical(y_test, n_classes)
After having prepared the data, we will define the parameters of our model and instantiate it. We now import from Keras the functions that are necessary to building and training a fully connected neural network. Whereas the Dense class instantiates a dense layer, the Sequential class allows us to connect these Dense layers in a chain. Lastly, we import the Stochastic Gradient Descent optimizer such that we can perform gradient descent on the loss given to the model to update the model parameters. We create a model with two hidden layers. The first layer projects the reshaped h * w image input to 128 nodes, and the second layer projects the 128 nodes down to 10 nodes representing the number of classes in this problem:
n_hidden = 128
model = Sequential()
model.add(Dense(n_hidden, activation='tanh', input_dim=h*w))
model.add(Dense(n_classes, activation='softmax'))
model.summary()
After defining our model, we define the optimizer's parameters that will be used to update the weights of our model given the loss. We choose a small learning of 0.001 and use the defaults for the other parameters:
sgd = SGD(lr=0.001)
Finally, we compile the graph of our model setting the loss function to categorical_crossentropy, which is used in classification problems where each sample belongs to a single class. We use accuracy as the reported metric because for this problem we are interested in increasing the accuracy metric of our model:
model.compile(loss='categorical_crossentropy', optimizer=sgd, metrics=['accuracy'])
We train our model for as many epochs as necessary. One epoch is equivalent to a pass through the entire training data. The batch size is chosen such that it maximizes memory performance by maxing out memory footprint during training. This is very important, especially when using GPUs, such that our models use all the resources available in parallel:
model.fit(X_train, y_train, epochs=10, batch_size=128)
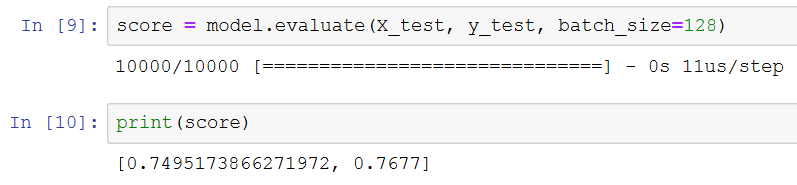
After training the model, we can check whether our model is generalizing to data that it has not seen by looking at our model's performance on the test data:
score = model.evaluate(X_test, y_test, batch_size=128)
print(score)
The preceding code block generates the following output: