























































A complex pipeline
In this section, we will determine the best classifier to predict the species of an Iris flower using its four different features. We will use a combination of four different data preprocessing techniques along with four different ML algorithms for the task. The following is the pipeline design for the job:
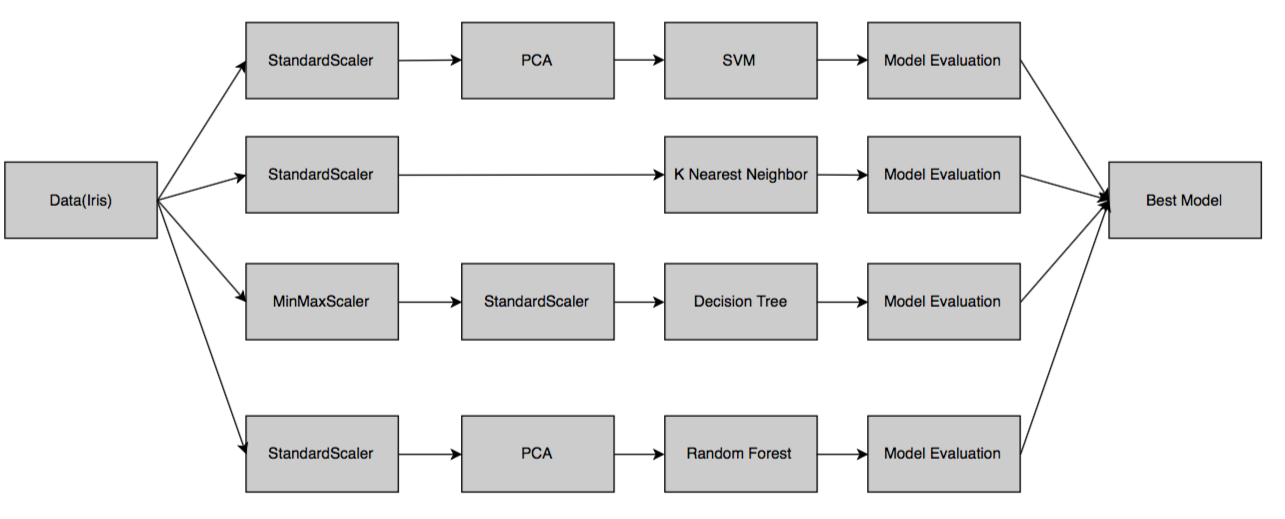
We will proceed as follows:
- We start with importing the various libraries and functions that are required for the task:
from sklearn.datasets import load_iris from sklearn.preprocessing import StandardScaler from sklearn.decomposition import PCA from sklearn.preprocessing import MinMaxScaler from sklearn.model_selection import train_test_split from sklearn.neighbors import KNeighborsClassifier from sklearn.ensemble import RandomForestClassifier from sklearn import svm from sklearn import tree from sklearn.pipeline import Pipeline
- Next, we load the
Irisdataset and split it intotrainandtestdatasets. TheX_trainandY_traindataset will be used for training the different...
















