























































HDFS health and FSCK
The health of the filesystem is very important for data retrieval and optimal performance. In a distributed system, it becomes more critical to maintain the good health of the HDFS filesystem so as to ensure block replication and near-parallel streaming of data blocks.
In this recipe, we will see how to check the health of the filesystem and do repairs, if any are needed.
Getting ready
Make sure you have a running cluster that has already been up for a few days with data. We can run the commands on a new cluster as well, but for the sake of this lab, it will give you more insights if it is run on a cluster with a large dataset.
How to do it...
ssh to the
master1.cyrus.comNamenode and change the user tohadoop.To check the HDFS root filesystem, execute the
hdfs fsck /command, as shown in the following screenshot: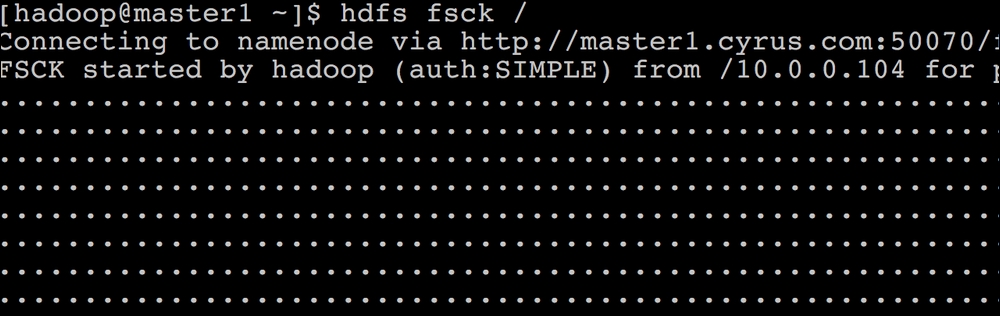
We can also check the status of just one file instead of the entire filesystem, as shown in the following screenshot:
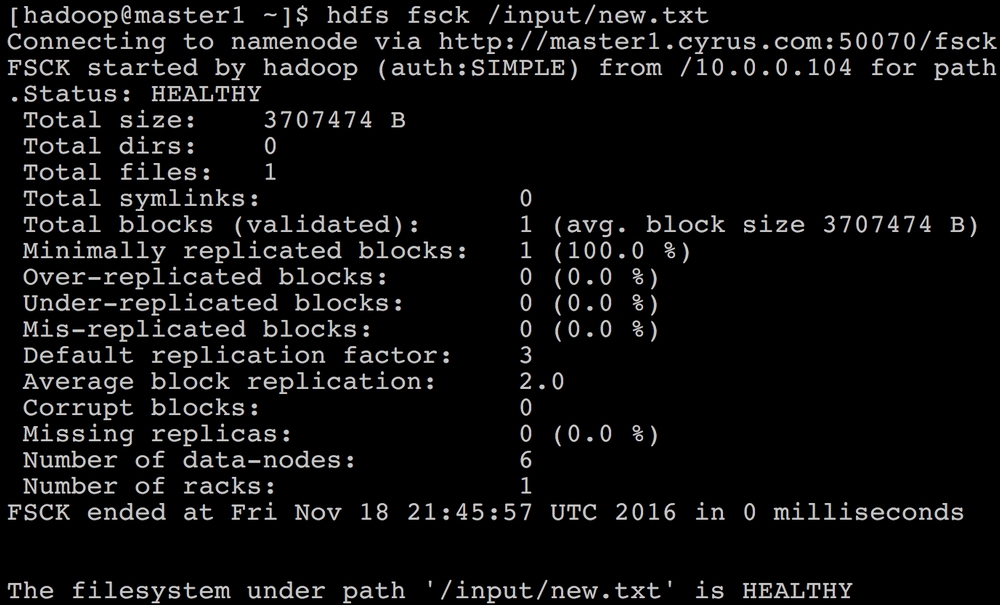
The output of the
fsckcommand will show the...









