























































Using DataFrames instead of RDDs
Just to drive home how you can actually use DataFrames instead of RDDs, let's go through an example of actually going to one of our earlier exercises that we did with RDDs and do it with DataFrames instead. This will illustrate how using DataFrames can make things simpler. We go back to the example where we figured out the most popular movies based on the MovieLens DataSet ratings information. If you want to open the file, you'll find it in the download package as popular-movies-dataframe.py, or you can just follow along typing it in as you go. This is what your file should look like if you open it in your IDE:
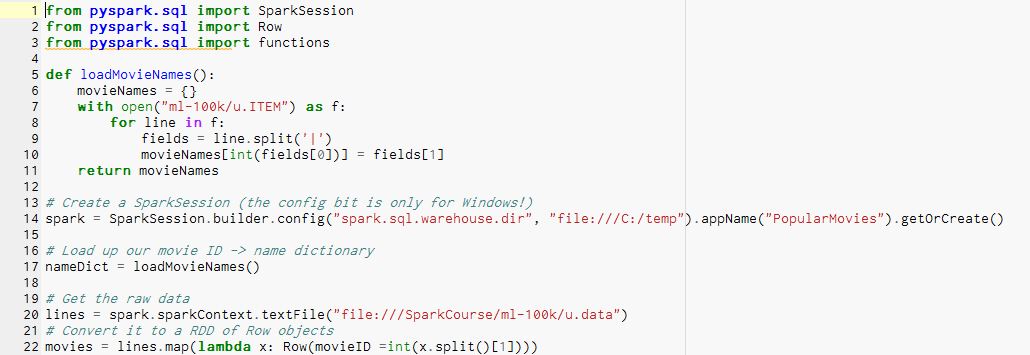
Let's go through this in detail. First comes our import statements:
from pyspark.sql import SparkSession from pyspark.sql import Row from pyspark.sql import functions
We start by importing SparkSession, which again is our new API in Spark 2.0 for doing DataFrame and DataSet operations. We will import the Row class and functions, so we can do SQL functions...














