























































Running the script - discover who the most popular superhero is
Let's dive into the code for finding the most popular superhero in the Marvel Universe and get our answer. Who will it be? We'll find out soon. Go to the download package for this book and you're going to download three things: the Marvel-graph.txt data file, which contains our social network of superheroes, the Marvel-names.txt file, which maps superhero IDs to human-readable names, and finally, the most-popular-superhero script. Download all that into your SparkCourse folder and then open up most-popular-superhero.py in your Python environment:
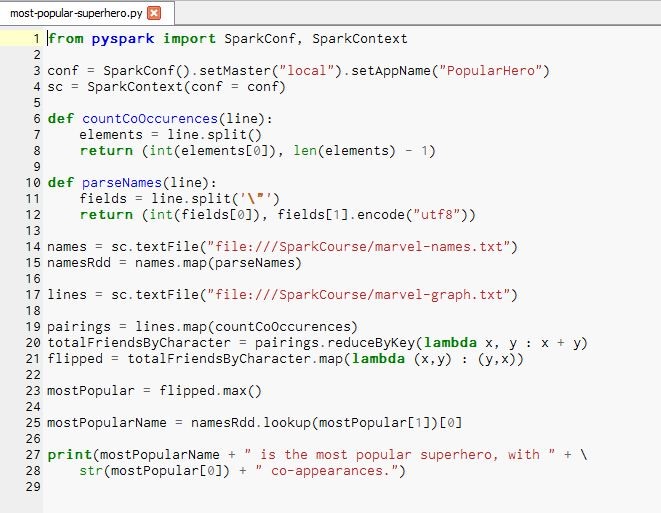
Alright, let's see what's going on here. We have the usual stuff at the top so let's get down to the meat of it
Mapping input data to (hero ID, number of co-occurrences) per line
The first thing we do, if you look at line 14, is load up our names.txt file into an RDD called names using sc.textFile:
names = sc.textFile("file:///SparkCourse/marvel-names.txt") We're going to do this name...














