























































Cosine similarity computes the cosine of the angle between two multidimensional projected vectors. It indicates how two documents are related to each other. Two vectors can be made of the bag of words or TF-IDF or any equivalent vector of the document. It is useful where the duplication of words matters. Cosine similarity can measure text similarity irrespective of the size of documents.
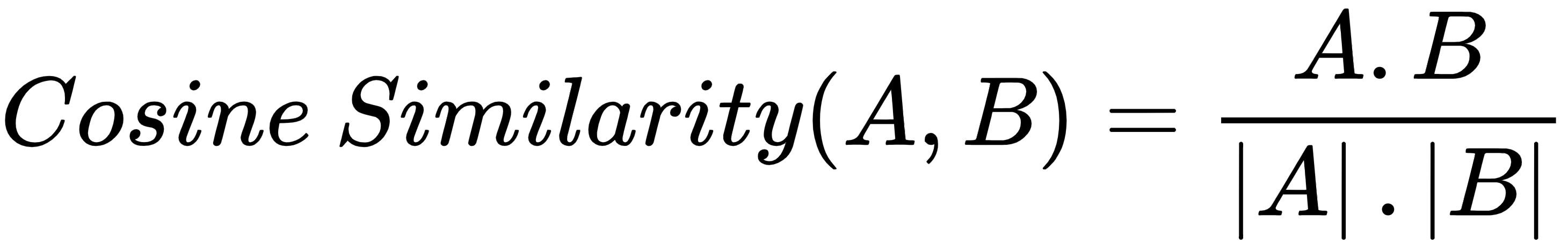
Let's look at a cosine similarity example:
# Let's import text feature extraction TfidfVectorizer
from sklearn.feature_extraction.text import TfidfVectorizer
docs=['I love pets.','I hate pets.']
# Initialize TfidfVectorizer object
tfidf= TfidfVectorizer()
# Fit and transform the given data
tfidf_vector = tfidf.fit_transform(docs)
# Import cosine_similarity metrics
from sklearn.metrics.pairwise import cosine_similarity
# compute similarity using cosine similarity
cos_sim=cosine_similarity(tfidf_vector, tfidf_vector)
print(cos_sim)
This results in the following output...
















