























































Caching tools
For microservices and modern web applications, the cache is not the only tool that exempts the database. It is a matter of strategy. Something that can be widely used to make the application much more performative than it would be without caches. But choosing well and setting the cache layer are crucial to success.
There are cache strategies consisting of using the cache as a loading point for the database. Observe the following diagram:
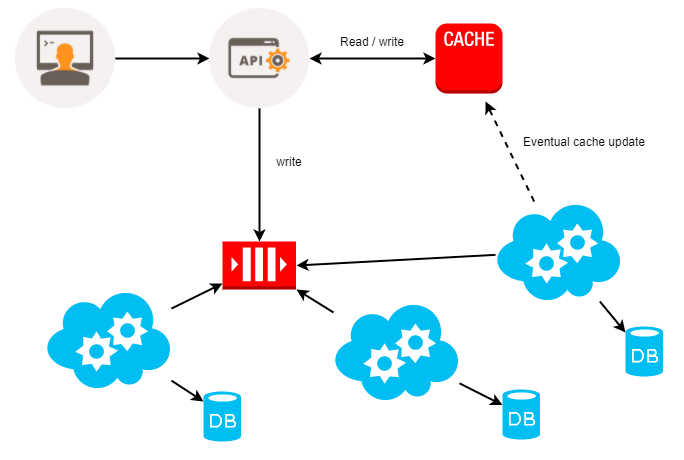
In the preceding diagram, we see that the requests arrive for our API, but are not directly processed and sent to the database. All valid requests are cached and simultaneously put in a row.
Consumers read the queue and process the information. Only after processing the information is the data stored in the database. Eventually, it is rewritten in the cache for data updates that are being consolidated in the database. With this strategy, any information requested by the API will be placed directly in the cache before it passes through the database, so that the database has the time required for processing.
For the end user, 200 is the HTTP response that is sent as soon as the data is stored in the cache, and not only after the registration of the information in the database, but also as this process occurs in an asynchronous way.
To have the possibility of this kind of strategy, we have to analyze the tools we have available. The best known on the market are:
- Memcached
- Redis
Let's look at the features of each.
Memcached
When it comes to Memcached, caching is one of the most known and mature markets. It has a key scheme/value storage for very efficient memory.
For the classic process of using cache, Memcached is simple and practical to use. The performance of Memcached is fully linked to the use of memory. If Memcached uses the disc to register any data, the performance is seriously compromised; moreover, Memcached does not have any record of disk capacity and always depends on third-party tools for this.
Redis
Redis can be practically considered as a new standard for the market when it comes to cache. Redis is effectively a database key/value, but because of stupendous performance, it has ended up being adopted as a caching tool.
The Redis documentation is very good and easy to understand; even a simple concept is equipped with many features such as pub/sub and queues.
Because of its convenience, flexibility, and internal working model, Redis has practically relegated all other caching systems to the condition of the legacy project.
Control of the Redis memory usage is very powerful. Most cache systems are very efficient to write and read data from memory, but not to purge the data and return memory to use. Redis again stands out in this respect, having good performance to return memory for use after purging data.
Unlike Memcached, Redis has native and extremely configurable persistence. Redis has two types of storage form, which are RDB and AOF.
The RDB model makes data persistent by using snapshots. This means that, within a configurable period of time, the information in memory is persisted on disk. The following is an example of a Redis configuration file using the RDB model of persistence:
save 60 1000stop-writes-on-bgsave-error nordbcompression yesdbfilename dump.rdb
The settings are simple and intuitive. First, we have to save the configuration itself:
save 60 1000The preceding line indicates that Redis should do the snapshot to persist the data home for 60 seconds, if at least 1,000 keys are changed. Changing the line to something like:
save 900 1Is the same as saying to Redis persist a snapshot every 15 minutes, if at least one key is modified.
The second line of our sample configuration is as follows:
stop-writes-on-bgsave-error noIt is telling Redis, even in case of error, to move on with the process and persistence attempts. The default value of this setting is yes, but if the development team decided to monitor the persistence of Redis the best option is no.
Usually, Redis compresses the data to be persisted to save disk usage; this setting is:
rdbcompression yes But if the performance is critical, with respect to the cache, this value can be modified to no. But the amount of disk consumed by Redis will be much higher.
Finally, we have the filename which will be persisted data by Redis:
dbfilename dump.rdbThis name is the default name in the configuration file but can be modified without major concerns.
The other model is the persistence of AOF. This model is safer with respect to keeping the recorded data. However, there is a higher cost performance for Redis. Under a configuration template for AOF:
appendonly noappendfsync everysec
The first line of this example presents the command appendonly. This command indicates whether the AOF persistence mode must be active or not.
In the second line of the sample configuration we have:
appendfsync everysecThe policy appendfsync active fsync tells the operating system to perform persistence in the fastest possible disk and not to buffer. The appendfsync has three configuration modes—no, everysec, and always, as shown in the following:
- no: Disables
appendfsync - everysec: This indicates that the storage of data should be performed as quickly as possible; usually this process is delayed by one second
- always: This indicates an even faster persistence process, preferably immediately
You may be wondering why we are seeing this part of Redis persistence. The motivation is simple; we must know exactly what power we gain from the persistent cache and how we can apply it.
Some development teams are also using Redis as a message broker. The tool is very fast in this way, but definitely not the most appropriate for this task, due to the fact that there are no transactions in the delivery of messages. With so many, messages between microservices could be lost. The situation where Redis expertly performs its function is as a cache.






