























































CQRS – query strategy
CQRS is a very important concept and one that you need to know. I always say that every architect has a toolbox and CQRS is the kind of tool that needs to be present in your box.
What is CQRS?
CQRS means Command Query Responsibility Segregation. As the name implies, it is about separating the responsibility of writing and reading of data. CQRS is a code pattern and not an architectural pattern.
Let's understand the classic scenarios of everyday life and, then, we will see how CQRS could be applied as a solution.
With the growth of the internet, we cannot think of creating applications for a few users; most of the new applications have premises of scalability, performance, and availability. How can an application work well with both tens and thousands of users simultaneously? It is complex to create a model that meets those needs. Databases, when required, can become a bottleneck.
Let's consider a financial credit system. People use this to get fast credit for special purchases in stores. The access to data change can at times be easy one moment or intense another moment.
The answer to this type of problem may lie in scaling the application in n servers. We can migrate to cloud-computing and create a script autoscaling to scale, as per demand.
The concept of scalability of the application will solve some problems of availability, such as supporting many users simultaneously without compromising the performance of the application.
Will just scaling the application servers solve all our problems?
Deadlocks, timeouts, and slowness mean that your database may be in too much demand.
More instances of an application is not a guarantee that the application will always be available. In this scenario, the application is totally dependent on the availability of the database.
Database scalability can be much more complex and expensive than scaling application servers. However, it is usually due to database consumption that applications have performance problems.
Complex queries can be performed to obtain database data. ORMs can add even more complexity to the data filtering process by mapping entities and filtering data by using joins in different tables.
Content obsolescence could be true. A limited set of data is constantly consulted and changed by a large number of users. This means that one data displayed on the screen may already have been changed by another. It is possible to state that all information displayed may already be obsolete.
Understanding CQRS
To have multiple servers consuming a single database that serves as both reading and writing can lead to many points of slowness in manipulating data and cause various problems in performance. The whole process of the business rule that will get the display data takes extra time in processing. Finally, we still have to consider the fact that the data displayed can be out of date.
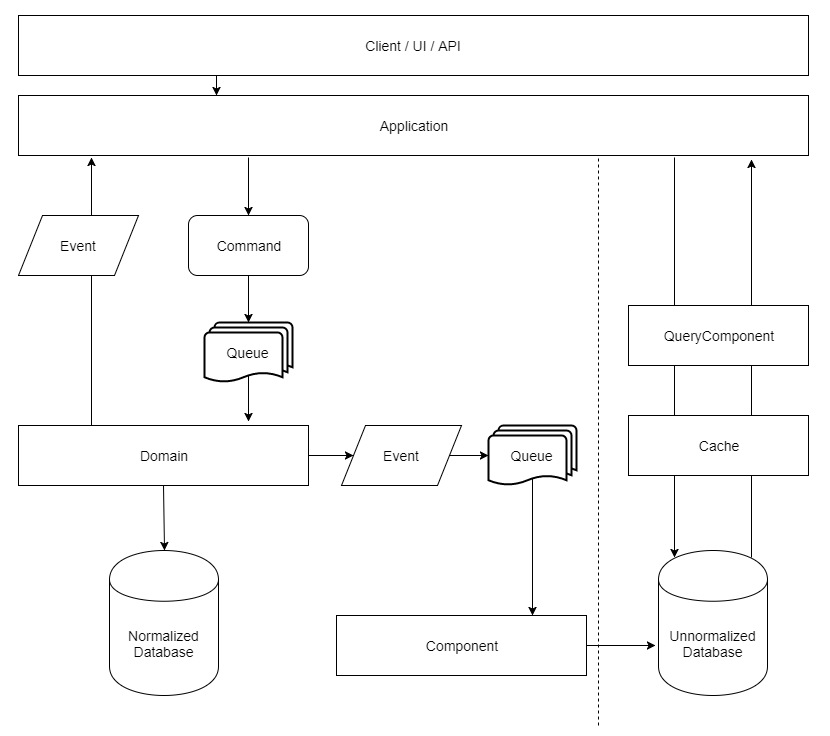
The CQRS teaches us the division of responsibility for writing and reading data, both conceptual and using different physical storages. This means that there will be separate means for recording and retrieving data from the databases. Queries are done synchronously in a separate denormalized database, and writes asynchronously to a normalized database. Caching first is still a type of CQRS implementation at the conceptual level.
Definitely, the CQRS does not have to be applied in every process of an application, only when there is a real need for optimization. A DDD-based modeling a Bounded Context (http://www.microsofttranslator.com/bv.aspx?from=pt&to=en&r=true&a=http%3A%2F%2Fwww.eduardopires.net.br%2F2016%2F03%2Fddd-bounded-context%2F) may implement the CQRS, while others do not.
The implementation of CQRS can be very simple or very complex, depending on the need of the application. Regardless of how it is implemented, CQRS always brings in extra complexity, and so it is necessary to evaluate the scenarios in which it is really required to work with this pattern. The basic idea is to segregate the responsibilities of the application in two parts. The Command will be responsible for modifying the state of the data in the application, and the Query that is the operation responsible for retrieving information from the database.
We could think of it as similar to separating CommandStack responsibilities and QueryStack in an n-tier architecture.
- QueryStack is relatively simple, as it is the responsibility of it to retrieve data that is almost ready for display. We can say that QueryStack is a synchronous layer that retrieves data from a denormal reading.
This bank may be a denormalized NoSQL as MongoDB (https://www.microsofttranslator.com/bv.aspx?from=pt&to=en&a=https%3A%2F%2Fwww.mongodb.com%2F), Redis (https://www.microsofttranslator.com/bv.aspx?from=pt&to=en&a=http%3A%2F%2Fredis.io%2F), RavenDB (https://www.microsofttranslator.com/bv.aspx?from=pt&to=en&a=https%3A%2F%2Fravendb.net%2F), or any other on the market. The denormal concept can be applied with one table per view, or as a flat query that returns all the data needed to be displayed.
The use of a flat query in an unnormalized bank avoids the need for joins, making queries much faster. We must accept that there will be duplication of data in order to meet this model.
- CommandStack: CommandStack is potentially asynchronous. It is in CommandStack where entities, business rules, and other processes will be. Thinking in DDD, the domain belongs to this segment of the application. CommandStack follows a behavior-centric approach where all business intention is initially triggered by the client. We use the concept of commands to represent a business intent. The commands declared are of imperative form, are raised asynchronously in the form of events, are interpreted by
CommandHandlers, and return a success or failure.
Whenever a command is triggered and changes the state of an entity in writing, a database process should be raised for the agents that will update the data needed in the backseat reading.
Synchronization: The following are some strategies to keep the foundations of reading and recording synchronized, and it is necessary to choose the one that best meets your scenario:
- Automatic updating: All changes in the state of a given recording database raise a synchronous process to update on the bench
- Update possible: All state changes of a given recording database trigger an asynchronous process to update the reading bank, offering an eventual data consistency
- Controlled update: A regular process and schedule is raised to synchronize the databases
- Update on demand: Every query checks the consistency of the read base compared to the recording, and forces an update if it is out of date
Any update is one of the most used strategies, because it assumes that any given displayed data may already be out of date, so it is not necessary to impose a synchronous update process.
Queueing: Many CQRS implementations may require a message broker for the processing of commands and events. In this case, we have an implementation, as shown in the following diagram:
Advantages and disvantages of implementing CQRS
The CQRS presents a different concept from the classic monolithic, where the whole process of writing and reading passes through the same layers and compete with each other in the processing of business rules and database usage. The concepts that are involved with CQRS provide us with greater scalability and availability. It is important to list some of the following positive aspects:
- The commands are asynchronous and processed in the queue so as to reduce the waiting time
- Writing and reading data do not compete for the same resources
- Queries on QueryStack are made separately and independently and do not depend on CommandStack processing
- It is possible to scale the CommandStack processes and QueryStack processes separately
- Expressive domain representation using the ubiquitous language in business intentions and other DDD concepts
The CQRS has many advantages for an application, but we must also talk about some disadvantages:
- CQRS is not easy. There is extra complexity in your application as well as a clear understanding of the domain and the ubiquitous language.
- Further attention is required when using the eventual consistency model. This concept is not mandatory, but requires more attention.
- Depending on the implementation, especially if you use the strategy of eventual consistency, it is common to adopt the use of a message broker. This increases application complexity and component monitoring.
It is important to note that CQRS is not an architectural pattern and can be understood as a form of componentizing part of your application. A common misconception is that CQRS should always be used in conjunction with event sourcing. Event sourcing has a strong connection with CQRS, and is easily implemented, since we also have CQRS. However, it is possible to implement event sourcing independent of CQRS.
Definitely, CQRS is an incredible pattern and it should be explored in any type of application, especially with microservices. The flexibility of scalability and the high availability we gain from adopting the pattern outweigh any additional complexity.






