























































Chapter 3: Fundamentals of Natural Language Processing
Activity 3: Process a Corpus
Solution
- Import the sklearn TfidfVectorizer and TruncatedSVD methods:
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.decomposition import TruncatedSVD
- Load the corpus:
docs = []
ndocs = ["doc1", "doc2", "doc3"]
for n in ndocs:
aux = open("dataset/"+ n +".txt", "r", encoding="utf8")
docs.append(aux.read())
- With spaCy, let's add some new stop words, tokenize the corpus, and remove the stop words. The new corpus without these words will be stored in a new variable:
import spacy
import en_core_web_sm
from spacy.lang.en.stop_words import STOP_WORDS
nlp = en_core_web_sm.load()
nlp.vocab["\n\n"].is_stop = True
nlp.vocab["\n"].is_stop = True
nlp.vocab["the"].is_stop = True
nlp.vocab["The"].is_stop = True
newD = []
for d, i in zip(docs, range(len(docs))):
doc = nlp(d)
tokens = [token.text for token in doc if not token.is_stop and not token.is_punct]
newD.append(' '.join(tokens))
- Create the TF-IDF matrix. I'm going to add some parameters to improve the results:
vectorizer = TfidfVectorizer(use_idf=True,
ngram_range=(1,2),
smooth_idf=True,
max_df=0.5)
X = vectorizer.fit_transform(newD)
- Perform the LSA algorithm:
lsa = TruncatedSVD(n_components=100,algorithm='randomized',n_iter=10,random_state=0)
lsa.fit_transform(X)
- With pandas, we are shown a sorted DataFrame with the weights of the terms of each concept and the name of each feature:
import pandas as pd
import numpy as np
dic1 = {"Terms": terms, "Components": lsa.components_[0]}
dic2 = {"Terms": terms, "Components": lsa.components_[1]}
dic3 = {"Terms": terms, "Components": lsa.components_[2]}
f1 = pd.DataFrame(dic1)
f2 = pd.DataFrame(dic2)
f3 = pd.DataFrame(dic3)
f1.sort_values(by=['Components'], ascending=False)
f2.sort_values(by=['Components'], ascending=False)
f3.sort_values(by=['Components'], ascending=False)
The output is as follows:
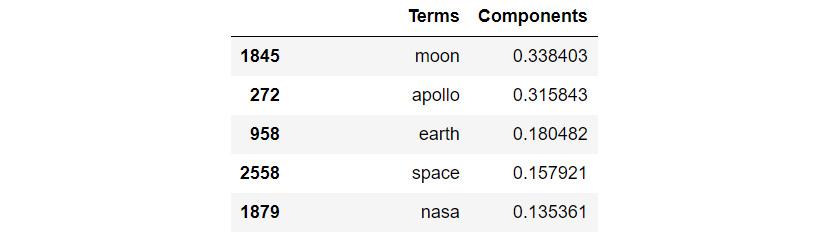
Figure 3.26: Output example of the most relevant words in a concept (f1)
Note:
Do not worry if the keywords are not the same as yours, if the keywords represent a concept, it is a valid result.
















