























































The TrendCalculus algorithm
In this section we will explain the detail of the TrendCalculus implementation, using the Brent oil price data set seen in Chapter 5, Spark for Geographic Analysis, as an example use case.
Trend windows
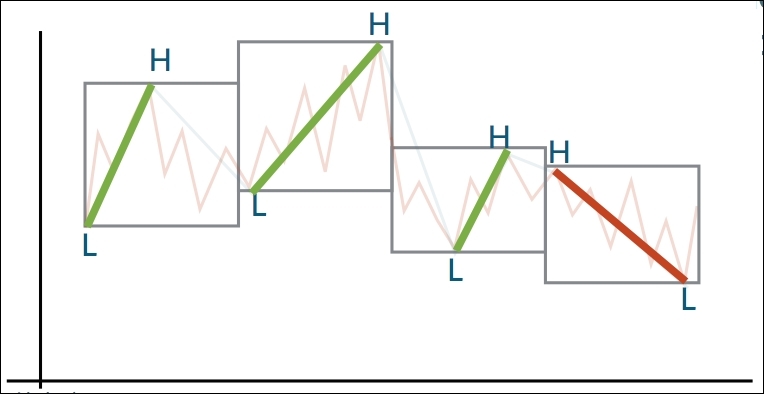
In order to measure any type of change, we must first quantify it in some way. For trends, we are going to define this in the following manner:
Overall positive change (usually expressed as a value increase)
Higher highs and higher lows => +1
Overall negative change (usually expressed as a value decrease)
Lower highs and lower lows => -1
We must therefore translate our data into a time series of trend direction, being either +1 or -1. By splitting our data into a series of windows, size n, we can calculate the dated highs and lows for each of them:
Since this type of windowing is a common practice in data science, it is reasonable to think there must be an implementation in Spark; if you have read Chapter 5, Spark for Geographic Analysis you will have seen them...













