























































Active and passive checks
To understand how to code a plugin we have first to grasp how, on a broad scale, a Nagios check works. There are two different kinds of checks:
Active check
Based on a time range, or manually triggered, an active check sees a plugin actively connecting to a service and collecting informations. A typical example could be a plugin to check the disk space: once invoked it interfaces with (usually) the operating system, execute a df command, works on the output, extracts the value related to the disk space, evaluates it against some thresholds and report back a status, like OK, WARNING, CRITICAL or UNKNOWN.
Passive check
In this case, Nagios does not trigger anything but waits to be contacted by some means by the service which must be monitored. It seems quite confusing but let’s make a real life example. How would you monitor if a disk backup has been completed successfully? One quick answer would be: knowing when the backup task starts and how long it lasts, we can define a time and invoke a script to check the task at that given hour. Nice, but when we plan something we must have a full understanding of how real life goes and a backup is not our little pet in the living room, it’s rather a beast which does what it wants. A backup can last a variable amount of time depending on unpredictable factor.
For instance, your typical backup task would copy 1 TB of data in 2 hours, starting at 03:00, out of a 6 TB disk. So, the next backup task would start at 03:00+02:00=05:00 AM, give or take some minutes, and you setup an active check for it at 05:30 and it works well for a couple of months. Then, one early morning your receive a notification on your smartphone, the backup is in CRITICAL. You wake up, connect to the backup console and see that at 06:00 in the morning you are asleep and the backup task has not even been started by the console. Then you have to wait until 08:00 AM until some of your colleagues shows up at the office to find out that the day before the disk you backup has been filled with 2 extra TB of data due to an unscheduled data transfer. So, the backup task preceding the one you are monitoring lasted not for a couple of hours but 6 hours, and the task you are monitoring then started at 09:30 AM.
Long story short, your active check has been fired up too early, that is why it failed. Maybe your are tempted to move your schedule some hours ahead, but simply do not do it, these time slots are not sliding frames. If you move your check ahead you should then move all the checks for the subsequent tasks ahead. You do it in one week, the project manager will ask someone to delete the 2 TB in excess (they are no more of any use for the project), and your schedules will be 2 hours ahead making your monitoring useless. So, as we insisted before, planning and analyzing the context are the key factors in making a good script and, in this case, a good plugin. We have a service that does not run 24/7 like a web service or a mail service, what is specific to the backup is that it is run periodically but we do not know exactly when.
The best approach to this kind of monitoring is letting the service itself to notify us when it finished its task and what was its outcome. That is usually accomplished using the ability of most of the backup programs to send a Simple Network Monitoring Protocol (SNMP) trap to a destination to inform it of the outcome and for our case it would be the Nagios server which would have been configured to receive the trap and analyze. Add to this an event horizon so that if you do not receive that specific trap in, let’s say, 24 hours we raise an alarm anyway and you are covered: whenever the backup task gets completed, or when it times out, we receive a notification.
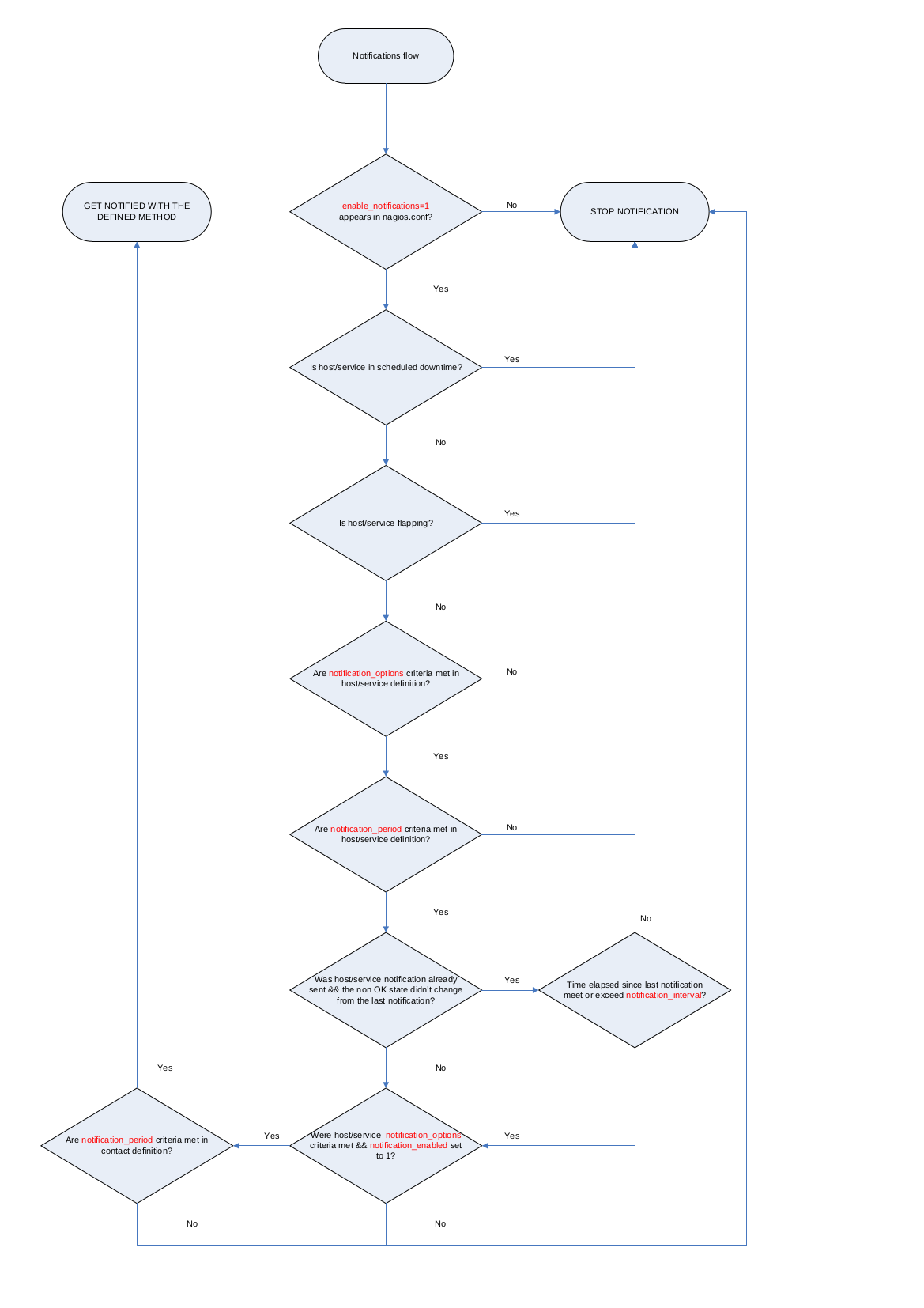
Nagios notifications flowchart













