























































Machine learning pipeline with an example
As discussed in the previous sections, one of the biggest features in the new ML library is the introduction of the pipeline. Pipelines provide a high-level abstraction of the machine learning flow and greatly simplify the complete workflow.
We will demonstrate the process of creating a pipeline in Spark using the StumbleUpon dataset.
Note
The dataset used here can be downloaded from http://www.kaggle.com/c/stumbleupon/data. Download the training data (train.tsv)--you will need to accept the terms and conditions before downloading the dataset. You can find more information about the competition at http://www.kaggle.com/c/stumbleupon.
Here is a glimpse of the StumbleUpon dataset stored as a temporary table using Spark SQLContext:
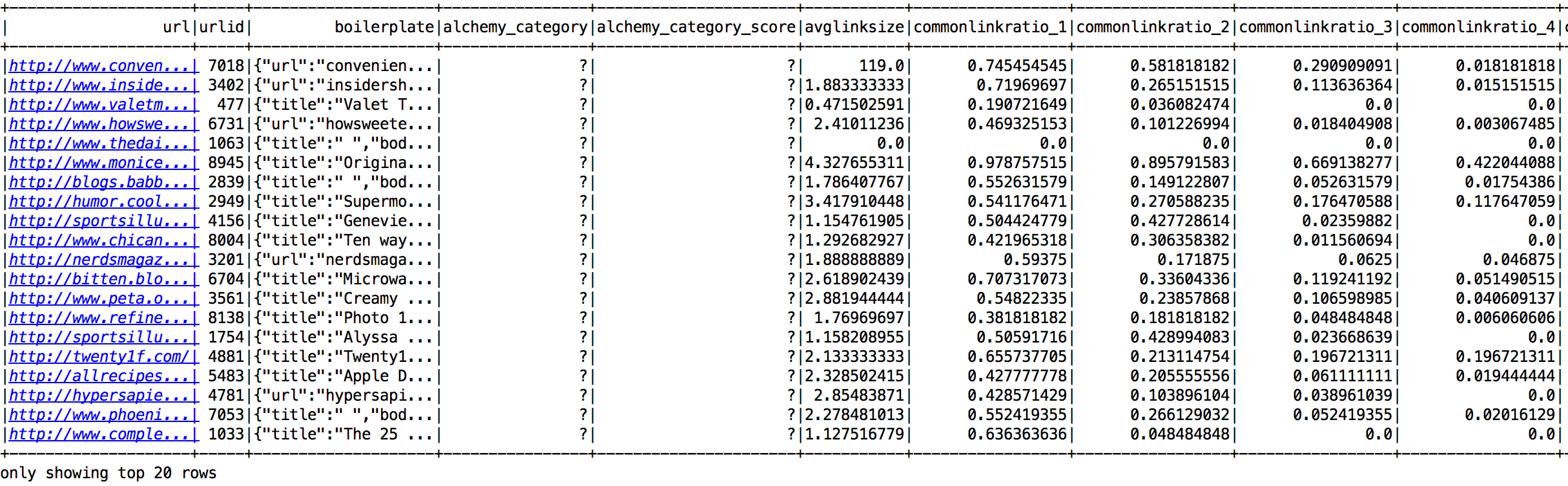
Here is a visualization of the StumbleUpon dataset:
StumbleUponExecutor
The StumbleUponExecutor object can be used to choose and run the respective classification model, for example, to run LogisiticRegression and execute the logistic...

















