























































Getting Spark running on Amazon EC2
The Spark project provides scripts to run a Spark cluster in the cloud on Amazon's EC2 service. These scripts are located in the ec2 directory. You can run the spark-ec2 script contained in this directory with the following command:
>./ec2/spark-ec2 Running it in this way without an argument will show the help output:
Usage: spark-ec2 [options] <action> <cluster_name> <action> can be: launch, destroy, login, stop, start, get-master Options: ...
Before creating a Spark EC2 cluster, you will need to ensure that you have anAmazon account.
Note
If you don't have an Amazon Web Services account, you can sign up at http://aws.amazon.com/.The AWS console is available at http://aws.amazon.com/console/.
You will also need to create an Amazon EC2 key pair and retrieve the relevant security credentials. The Spark documentation for EC2 (available at http://spark.apache.org/docs/latest/ec2-scripts.html) explains the requirements:
Create an Amazon EC2 key pair for yourself. This can be done by logging into your Amazon Web Services account through the AWS console, clicking on
Key Pairson the left sidebar, and creating and downloading a key. Make sure that you set the permissions for the private key file to 600 (that is, only you can read and write it) so that ssh will work.
Whenever you want to use the spark-ec2 script, set the environment variables
AWS_ACCESS_KEY_IDandAWS_SECRET_ACCESS_KEYto your Amazon EC2 access keyIDand secret access key, respectively. These can be obtained from the AWS homepage by clickingAccount|Security Credentials|Access Credentials.
When creating a key pair, choose a name that is easy to remember. We will simply use the name spark for the key pair. The key pair file itself will be called spark.pem. As mentioned earlier, ensure that the key pair file permissions are set appropriately and that the environment variables for the AWS credentials are exported using the following commands:
$ chmod 600 spark.pem $ export AWS_ACCESS_KEY_ID="..." $ export AWS_SECRET_ACCESS_KEY="..."
You should also be careful to keep your downloaded key pair file safe and not lose it, as it can only be downloaded once when it is created!
Note that launching an Amazon EC2 cluster in the following section will incur costs to your AWS account.
Launching an EC2 Spark cluster
We're now ready to launch a small Spark cluster by changing into the ec2 directory and then running the cluster launch command:
$ cd ec2 $ ./spark-ec2 --key-pair=rd_spark-user1 --identity-file=spark.pem --region=us-east-1 --zone=us-east-1a launch my-spark-cluster
This will launch a new Spark cluster called test-cluster with one master and one slave node of instance type m3.medium. This cluster will be launched with a Spark version built for Hadoop 2. The key pair name we used is spark, and the key pair file is spark.pem (if you gave the files different names or have an existing AWS key pair, use that name instead).
It might take quite a while for the cluster to fully launch and initialize. You should see something like the following immediately after running the launch command:
Setting up security groups... Creating security group my-spark-cluster-master Creating security group my-spark-cluster-slaves Searching for existing cluster my-spark-cluster in region us-east-1... Spark AMI: ami-5bb18832 Launching instances... Launched 1 slave in us-east-1a, regid = r-5a893af2 Launched master in us-east-1a, regid = r-39883b91 Waiting for AWS to propagate instance metadata... Waiting for cluster to enter 'ssh-ready' state........... Warning: SSH connection error. (This could be temporary.) Host: ec2-52-90-110-128.compute-1.amazonaws.com SSH return code: 255 SSH output: ssh: connect to host ec2-52-90-110-128.compute- 1.amazonaws.com port 22: Connection refused Warning: SSH connection error. (This could be temporary.) Host: ec2-52-90-110-128.compute-1.amazonaws.com SSH return code: 255 SSH output: ssh: connect to host ec2-52-90-110-128.compute- 1.amazonaws.com port 22: Connection refused Warnig: SSH connection error. (This could be temporary.) Host: ec2-52-90-110-128.compute-1.amazonaws.com SSH return code: 255 SSH output: ssh: connect to host ec2-52-90-110-128.compute- 1.amazonaws.com port 22: Connection refused Cluster is now in 'ssh-ready' state. Waited 510 seconds.
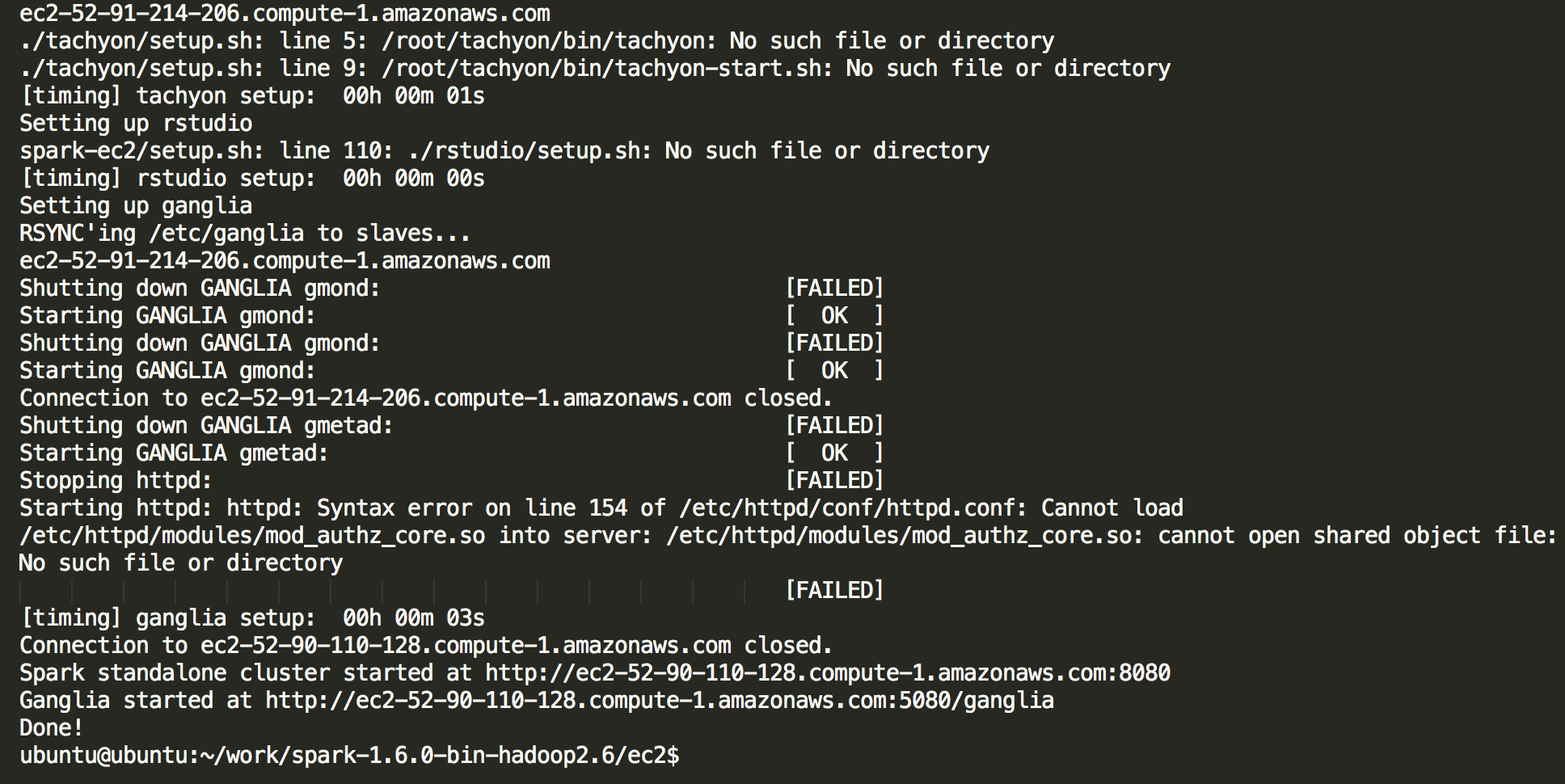
If the cluster has launched successfully, you should eventually see a console output similar to the following listing:
./tachyon/setup.sh: line 5: /root/tachyon/bin/tachyon: No such file or directory ./tachyon/setup.sh: line 9: /root/tachyon/bin/tachyon-start.sh: No such file or directory [timing] tachyon setup: 00h 00m 01s Setting up rstudio spark-ec2/setup.sh: line 110: ./rstudio/setup.sh: No such file or directory [timing] rstudio setup: 00h 00m 00s Setting up ganglia RSYNC'ing /etc/ganglia to slaves... ec2-52-91-214-206.compute-1.amazonaws.com Shutting down GANGLIA gmond: [FAILED] Starting GANGLIA gmond: [ OK ] Shutting down GANGLIA gmond: [FAILED] Starting GANGLIA gmond: [ OK ] Connection to ec2-52-91-214-206.compute-1.amazonaws.com closed. Shutting down GANGLIA gmetad: [FAILED] Starting GANGLIA gmetad: [ OK ] Stopping httpd: [FAILED] Starting httpd: httpd: Syntax error on line 154 of /etc/httpd /conf/httpd.conf: Cannot load /etc/httpd/modules/mod_authz_core.so into server: /etc/httpd/modules/mod_authz_core.so: cannot open shared object file: No such file or directory [FAILED] [timing] ganglia setup: 00h 00m 03s Connection to ec2-52-90-110-128.compute-1.amazonaws.com closed. Spark standalone cluster started at http://ec2-52-90-110-128.compute-1.amazonaws.com:8080 Ganglia started at http://ec2-52-90-110-128.compute- 1.amazonaws.com:5080/ganglia Done! ubuntu@ubuntu:~/work/spark-1.6.0-bin-hadoop2.6/ec2$
This will create two VMs - Spark Master and Spark Slave of type m1.large as shown in the following screenshot :
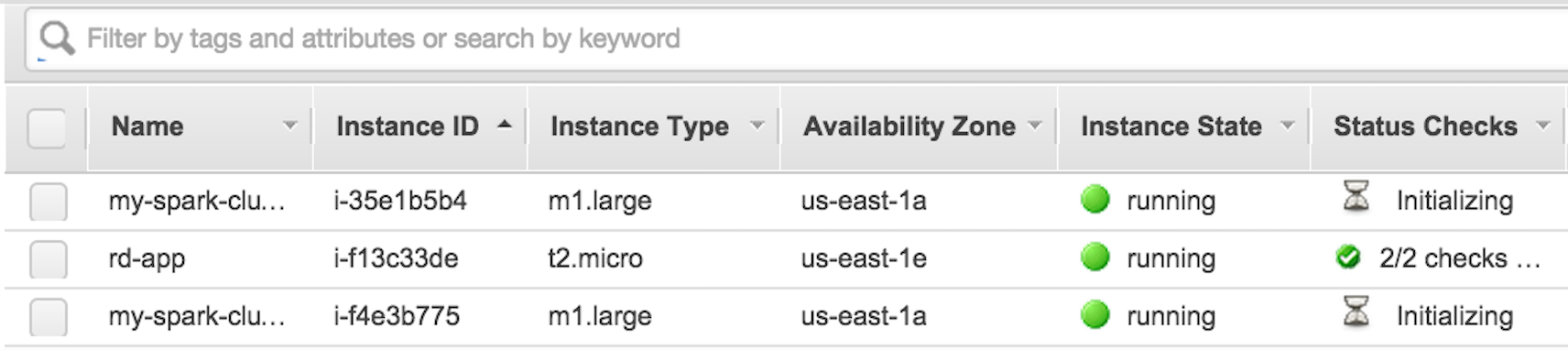
To test whether we can connect to our new cluster, we can run the following command:
$ ssh -i spark.pem root@ ec2-52-90-110-128.compute-1.amazonaws.comRemember to replace the public domain name of the master node (the address after root@ in the preceding command) with the correct Amazon EC2 public domain name that will be shown in your console output after launching the cluster.
You can also retrieve your cluster's master public domain name by running this line of code:
$ ./spark-ec2 -i spark.pem get-master test-clusterAfter successfully running the ssh command, you will be connected to your Spark master node in EC2, and your terminal output should match the following screenshot:
We can test whether our cluster is correctly set up with Spark by changing into the Spark directory and running an example in the local mode:
$ cd spark $ MASTER=local[2] ./bin/run-example SparkPi
You should see output similar to what you would get on running the same command on your local computer:
... 14/01/30 20:20:21 INFO SparkContext: Job finished: reduce at SparkPi.scala:35, took 0.864044012 s Pi is roughly 3.14032 ...
Now that we have an actual cluster with multiple nodes, we can test Spark in the cluster mode. We can run the same example on the cluster, using our one slave node by passing in the master URL instead of the local version:
$ MASTER=spark:// ec2-52-90-110-128.compute-
1.amazonaws.com:7077 ./bin/run-example SparkPi Note
Note that you will need to substitute the preceding master domain name with the correct domain name for your specific cluster.
Again, the output should be similar to running the example locally; however, the log messages will show that your driver program has connected to the Spark master:
... 14/01/30 20:26:17 INFO client.Client$ClientActor: Connecting to master spark://ec2-54-220-189-136.eu- west-1.compute.amazonaws.com:7077 14/01/30 20:26:17 INFO cluster.SparkDeploySchedulerBackend: Connected to Spark cluster with app ID app-20140130202617-0001 14/01/30 20:26:17 INFO client.Client$ClientActor: Executor added: app-20140130202617-0001/0 on worker-20140130201049- ip-10-34-137-45.eu-west-1.compute.internal-57119 (ip-10-34-137-45.eu-west-1.compute.internal:57119) with 1 cores 14/01/30 20:26:17 INFO cluster.SparkDeploySchedulerBackend: Granted executor ID app-20140130202617-0001/0 on hostPort ip-10-34-137-45.eu-west-1.compute.internal:57119 with 1 cores, 2.4 GB RAM 14/01/30 20:26:17 INFO client.Client$ClientActor: Executor updated: app-20140130202617-0001/0 is now RUNNING 14/01/30 20:26:18 INFO spark.SparkContext: Starting job: reduce at SparkPi.scala:39 ...
Feel free to experiment with your cluster. Try out the interactive console in Scala, for example:
$ ./bin/spark-shell --master spark:// ec2-52-90-110-128.compute-
1.amazonaws.com:7077Once you've finished, type exit to leave the console. You can also try the PySpark console by running the following command:
$ ./bin/pyspark --master spark:// ec2-52-90-110-128.compute-
1.amazonaws.com:7077You can use the Spark Master web interface to see the applications registered with the master. To load the Master Web UI, navigate to ec2-52-90-110-128.compute-1.amazonaws.com:8080 (again, remember to replace this domain name with your own master domain name).
Remember that you will be charged by Amazon for usage of the cluster. Don't forget to stop or terminate this test cluster once you're done with it. To do this, you can first exit the ssh session by typing exit to return to your own local system and then run the following command:
$ ./ec2/spark-ec2 -k spark -i spark.pem destroy test-clusterYou should see the following output:
Are you sure you want to destroy the cluster test-cluster? The following instances will be terminated: Searching for existing cluster test-cluster... Found 1 master(s), 1 slaves > ec2-54-227-127-14.compute-1.amazonaws.com > ec2-54-91-61-225.compute-1.amazonaws.com ALL DATA ON ALL NODES WILL BE LOST!! Destroy cluster test-cluster (y/N): y Terminating master... Terminating slaves...
Hit Y and then Enter to destroy the cluster.
Congratulations! You've just set up a Spark cluster in the cloud, run a fully parallel example program on this cluster, and terminated it. If you would like to try out any of the example code in the subsequent chapters (or your own Spark programs) on a cluster, feel free to experiment with the Spark EC2 scripts and launch a cluster of your chosen size and instance profile. (Just be mindful of the costs and remember to shut it down when you're done!)

















