























































Configuring and running Spark on Amazon Elastic Map Reduce
Launch a Hadoop cluster with Spark installed using the Amazon Elastic Map Reduce. Perform the following steps to create an EMR cluster with Spark installed:
- Launch an Amazon EMR Cluster.
- Open the Amazon EMR UI console at https://console.aws.amazon.com/elasticmapreduce/.
- Choose
Create cluster:
- Choose appropriate Amazon AMI Version 3.9.0 or later as shown in the following screenshot:
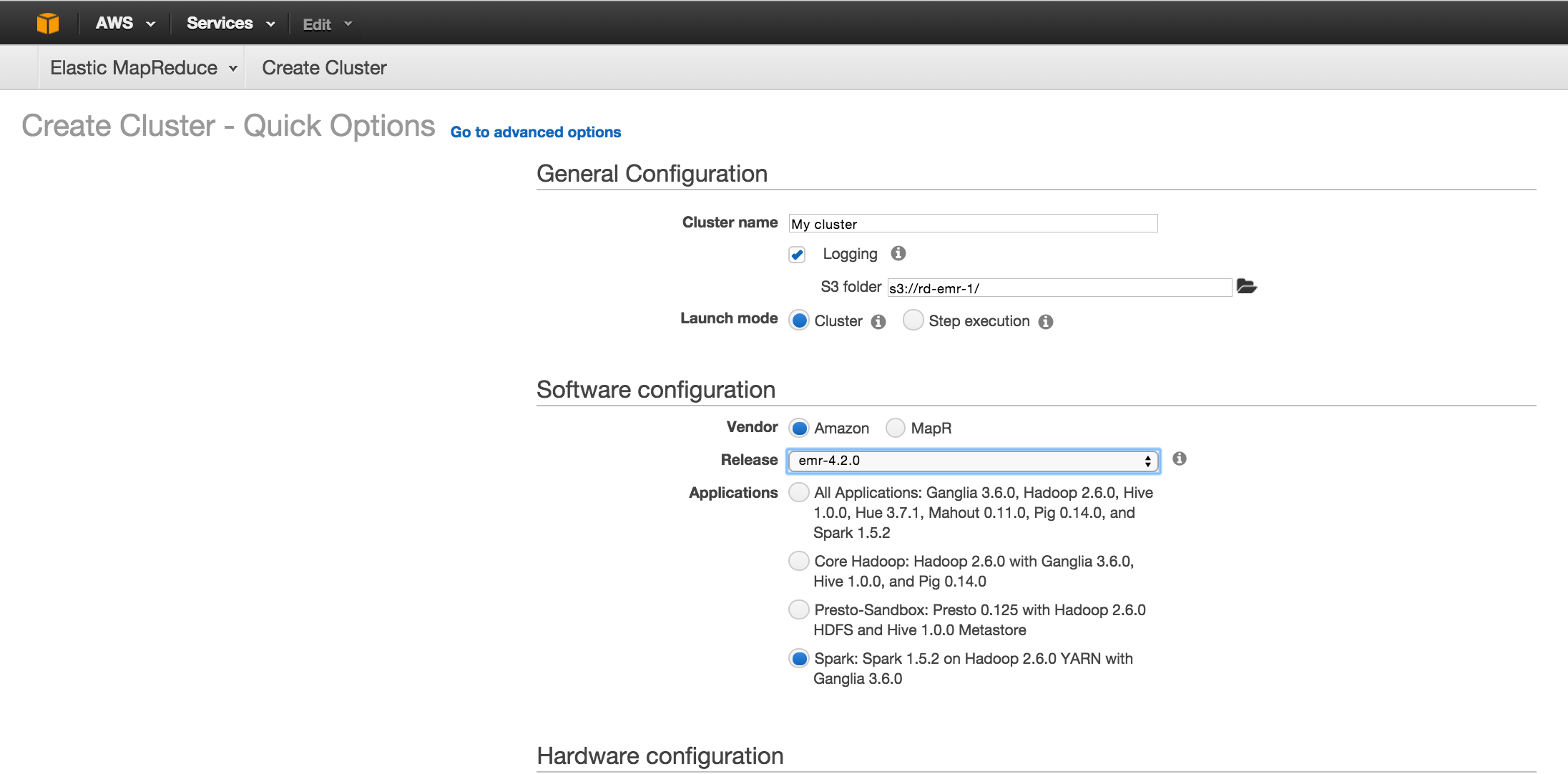
- For the applications to be installed field, choose
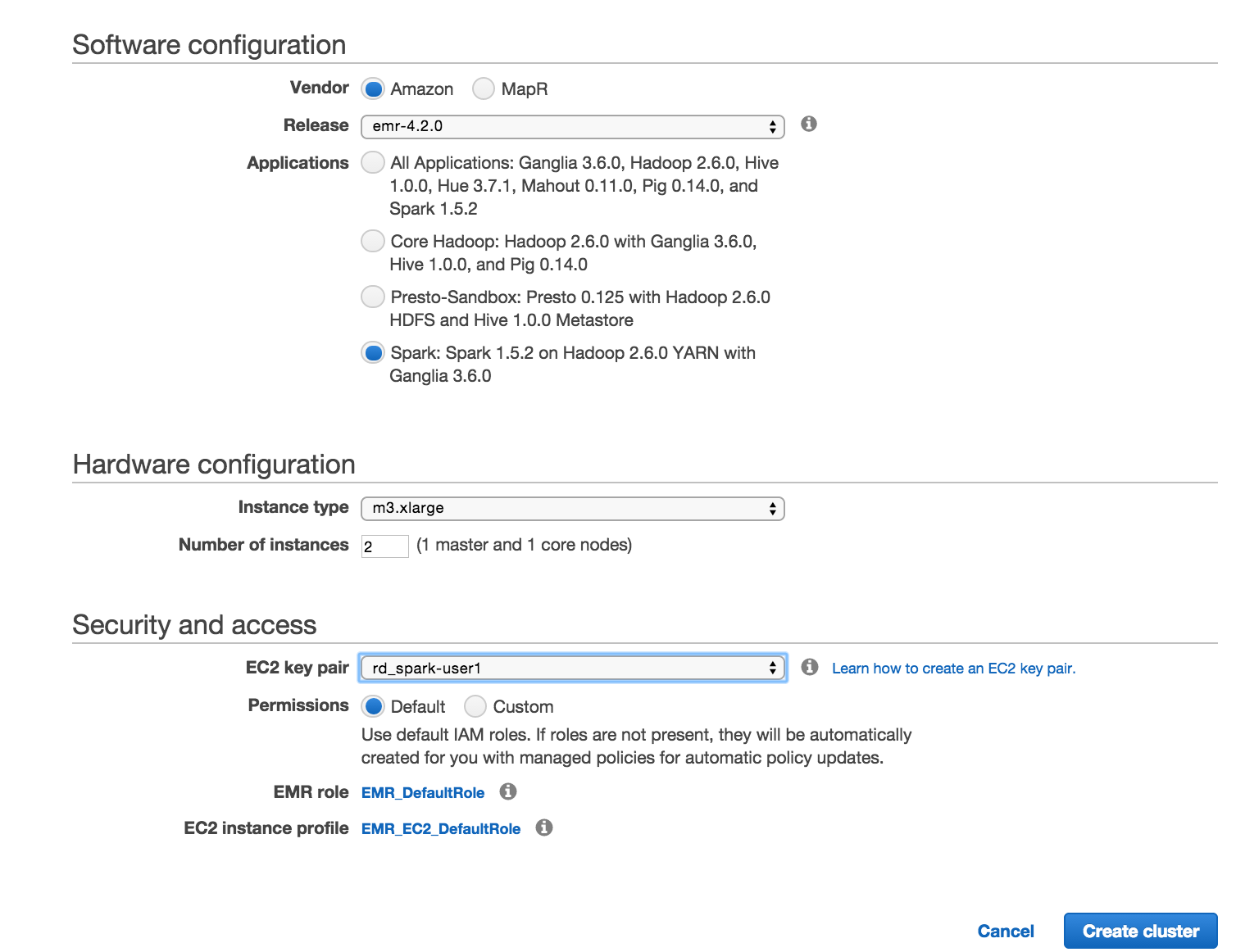
Spark 1.5.2or later from the list shown on theUser Interfaceand click onAdd. - Select other hardware options as necessary:
- The
Instance Type - The keypair to be used with SSH
Permissions- IAM roles (
DefaultorCustom)
- The
Refer to the following screenshot:
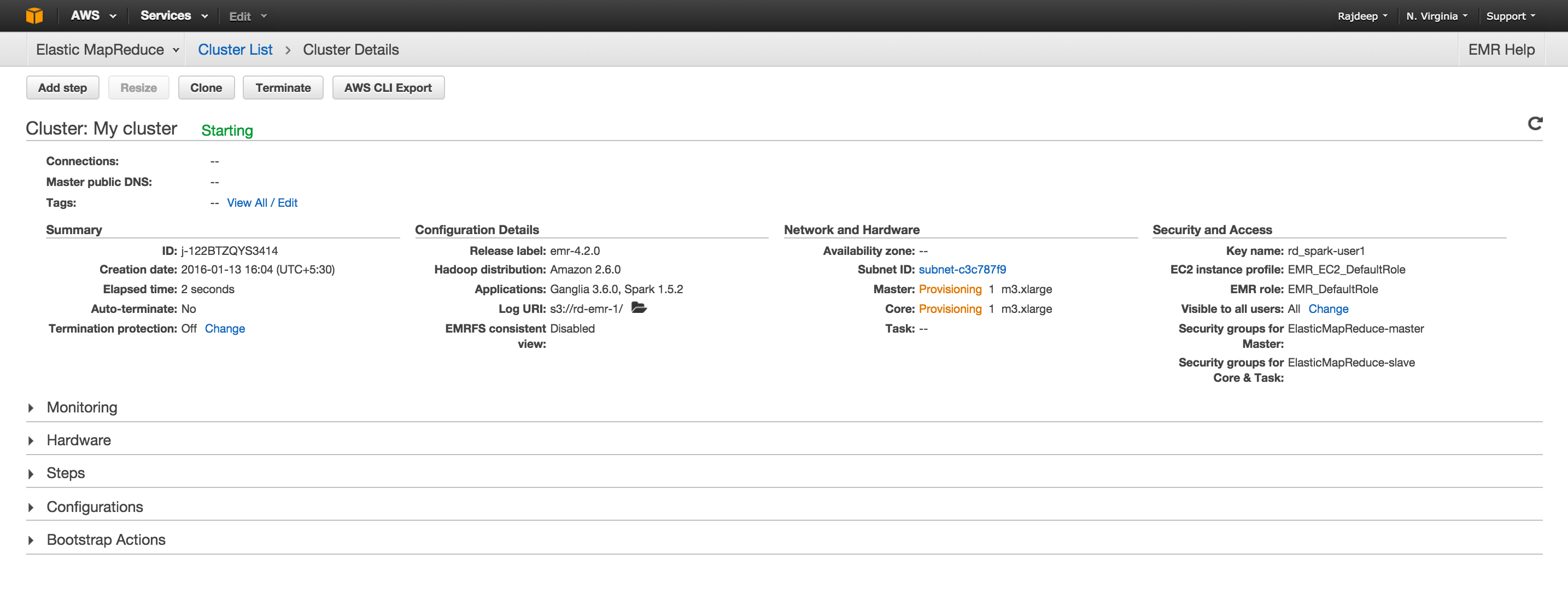
- Click on
Create cluster. The cluster will start instantiating as shown in the following screenshot:
- Log in into the master. Once the EMR cluster is ready, you can SSH into the master:
$ ssh -i rd_spark-user1.pem
[email protected] The output will be similar to following listing:
Last login: Wed Jan 13 10:46:26 2016 __| __|_ ) _| ( / Amazon Linux AMI ___|___|___| https://aws.amazon.com/amazon-linux-ami/2015.09-release-notes/ 23 package(s) needed for security, out of 49 available Run "sudo yum update" to apply all updates. [hadoop@ip-172-31-2-31 ~]$
- Start the Spark Shell:
[hadoop@ip-172-31-2-31 ~]$ spark-shell 16/01/13 10:49:36 INFO SecurityManager: Changing view acls to: hadoop 16/01/13 10:49:36 INFO SecurityManager: Changing modify acls to: hadoop 16/01/13 10:49:36 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(hadoop); users with modify permissions: Set(hadoop) 16/01/13 10:49:36 INFO HttpServer: Starting HTTP Server 16/01/13 10:49:36 INFO Utils: Successfully started service 'HTTP class server' on port 60523. Welcome to ____ __ / __/__ ___ _____/ /__ _ / _ / _ `/ __/ '_/ /___/ .__/_,_/_/ /_/_ version 1.5.2 /_/ scala> sc
- Run Basic Spark sample from the EMR:
scala> val textFile = sc.textFile("s3://elasticmapreduce/samples /hive-ads/tables/impressions/dt=2009-04-13-08-05 /ec2-0-51-75-39.amazon.com-2009-04-13-08-05.log") scala> val linesWithCartoonNetwork = textFile.filter(line => line.contains("cartoonnetwork.com")).count()
Your output will be as follows:
linesWithCartoonNetwork: Long = 9
















