























































The need for distributed caching in Storm
Now that we have explored Storm enough to understand all its strengths, let's touch on one of its biggest weaknesses: the lack of a shared cache, a common store in memory that all tasks running across the workers on various nodes in the Storm cluster can access and write to.
The following figure illustrates a three node Storm cluster where we have two workers running on each of the supervisor nodes:
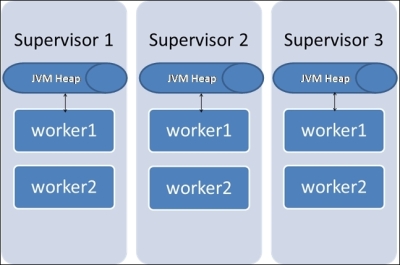
As depicted in the preceding figure, each worker has its own JVM where the data can be stored and cached. However, what we are missing here is a layer of cache that shares components within the workers on a supervisor as well as across the supervisors. The following figure depicts the need for what we are referring to:
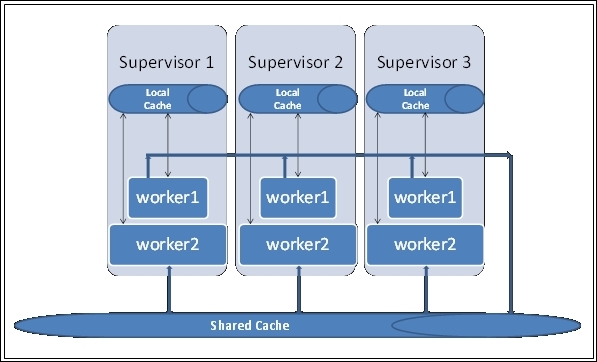
The preceding figure depicts the need for a shared caching layer where common data can be placed, which is referable from all nodes. These are very valid use cases because in production, we encounter scenarios such as the following:
We have...





