























































Reading and writing data in Excel format
Pandas supports reading data in Excel 2003 and newer formats, using the pd.read_excel() function or via the ExcelFile class. Internally, both techniques use either the XLRD or OpenPyXL packages, so you will need to ensure that one of them is installed in your Python environment.
For demonstration, a data/stocks.xlsx file is provided with the sample data. If you open it in Excel, you will see something similar to what is shown in the following screenshot:
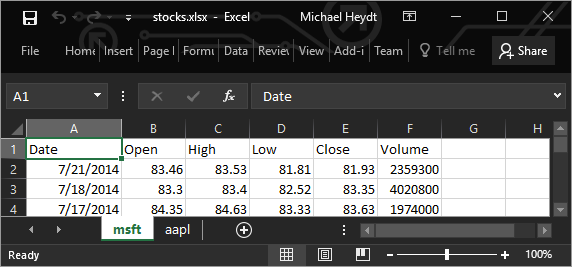
The workbook contains two sheets, msft and aapl, which hold the stock data for each respective stock.
The following then reads the data/stocks.xlsx file into a DataFrame:
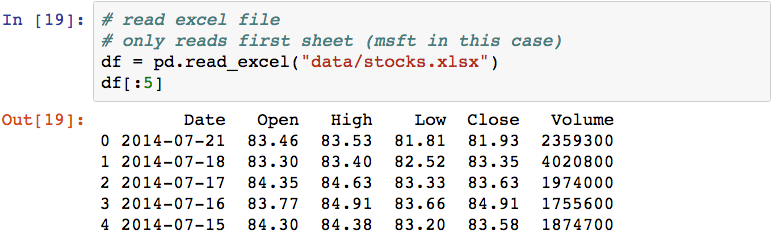
This has read only content from the first worksheet in the Excel file (the msft worksheet), and has used the contents of the first row as column names. To read the other worksheet, you can pass the name of the worksheet using the sheetname parameter:
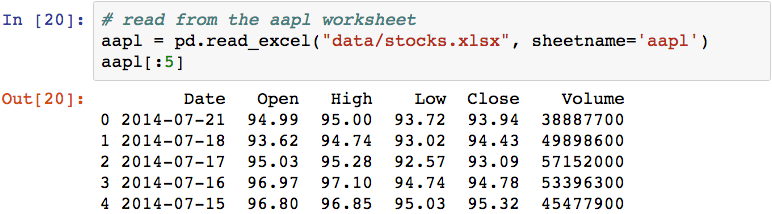
Like with pd.read_csv(), many assumptions are made about column names, data types, and...
















