























































Using AWS Glue and Amazon Athena
In this section, we will use AWS Glue to create a crawler, an ETL job, and a job that runs KMeans clustering algorithm on the input data.
We use a publicly available dataset about the students' knowledge status on a subject. The dataset and the field descriptions are available for download from the UCI site: https://archive.ics.uci.edu/ml/datasets/User+Knowledge+Modeling
- Log in to the AWS Management Console and go to the Glue console. Click on the
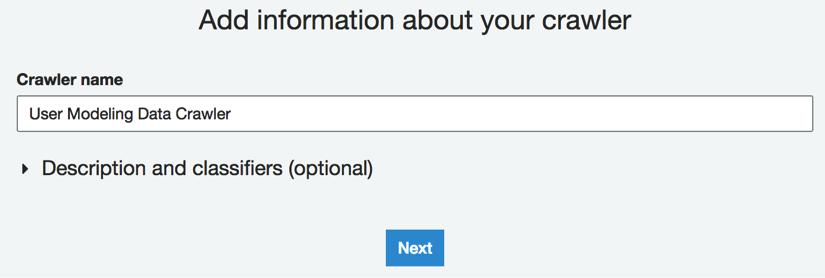
Add crawlerbutton. - Specify the
Crawler nameasUser Modeling Data Crawleras shown here. Click on theNextbutton:
- In the
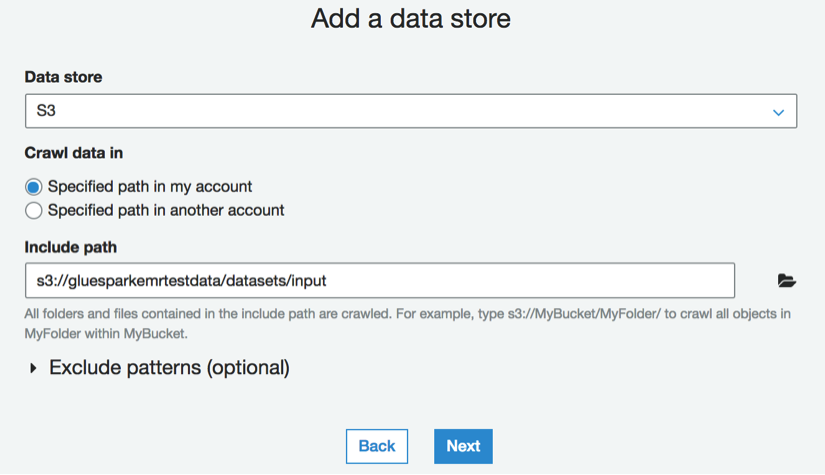
Add a data storescreen, selectS3as theData store, and select theSpecified path in my accountoption. Specify the path for the S3 bucket containing the input data. Click on theNextbutton:
- Select
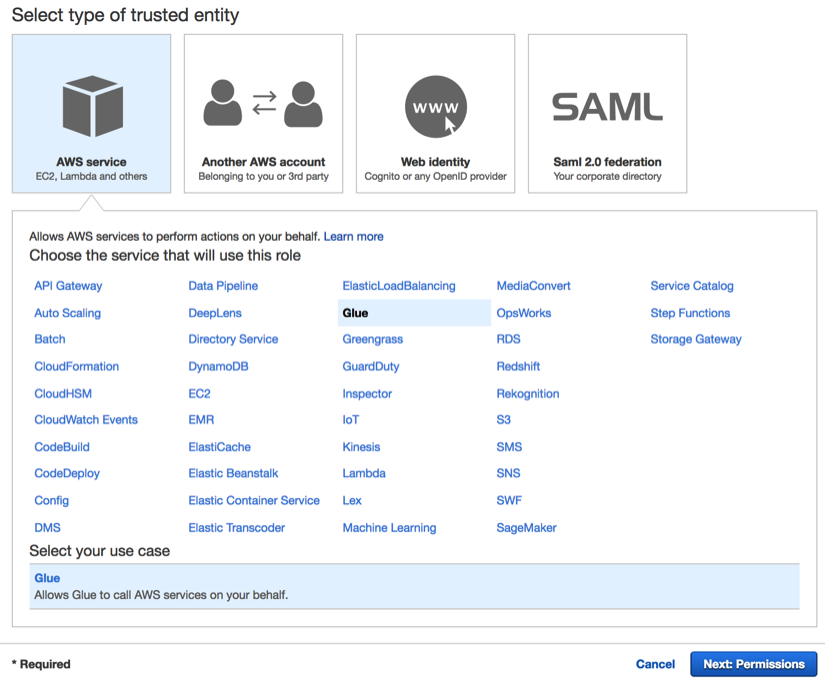
Noon theAdd another data storeand click on theNextbutton. - On the IAM console, select the
Glue serviceand click on theNext: Permissionsbutton:
- Next, we attach the appropriate policies to the role...














