























































Compound primary keys in column families
Now that we've established the relatively familiar-looking column family structure of users—a table with a simple primary key—let's move on to a table with a compound primary key. To start, let's take a look at home_status_updates, a fairly straightforward table. Recall that this table has a partition key timeline_username; a clustering column status_update_id; and two data columns, body and status_update_username column.
We'll use the LIST command to take a look at the contents of the column family and, beforehand, we'll use the ASSUME command to set the value output format to utf8. This has a similar effect as the AS modifier we used earlier, but it applies to all cells in a column family, rather than only cells with a specific name:
ASSUME home_status_updates VALIDATOR AS utf8; LIST home_status_updates;
The output of the LIST command takes the same general shape as that for the users column family, but the way the information is arranged might come as a surprise:

The output contains only a single RowKey, that is alice; it contains six cells with rather inscrutable names. Recall that in the Fully denormalizing the home timeline section of Chapter 6, Denormalizing Data for Maximum Performance, we populated the home_status_updates table with two status updates, both in alice's partition of the table. So how does the information in the column family line up with the information in the CQL table we're used to?
To answer this question, look closely at the names of the cells. Take the second cell, which has the name 16e2f240-2afa-11e4-8069-5f98e903bf02:body. This cell name appears to contain two pieces of information: a clustering column value and the name of a data column. The value of the cell is, straightforwardly, the value of the body column in the row with the status_update_id value 16e2f240-2afa-11e4-8069-5f98e903bf02.
The reason we only see one RowKey value is because all the rows in the home_status_updates table have the partition key alice. What cassandra-cli calls a RowKey is, in fact, exactly what we have been calling a partition key the entire time.
A complete mapping
With this insight, we can now generate a complete mapping between the components of a column family and the CQL-level table structure components they represent:
|
Column Family Component |
CQL3 Table Component |
|---|---|
|
|
Partition Key |
|
Cell name |
The values of clustering column(s), if any, followed by the name of the data column |
|
Cell value |
The value in the row/column identified by the partition key, clustering column(s), and the column name |
To reinforce this idea, let's apply our visualization from the previous section to the more complex structure of home_status_updates:
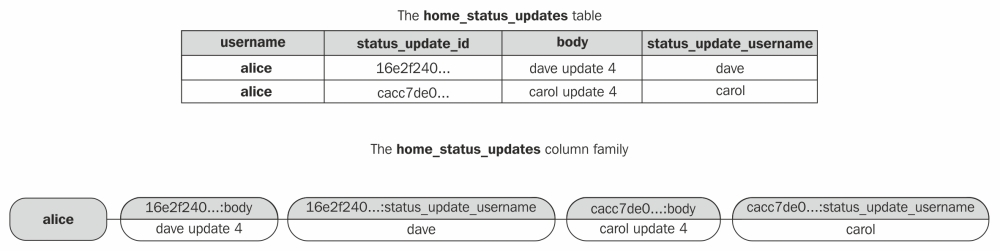
The main insight here is that every value in every row in alice's partition is stored in a one-dimensional data structure in the column family. At the column family level, nothing in the storage structure distinguishes the values in carol's status update row from the values in dave's status update row. The cells containing those values simply have different prefixes in their cell names; only at the CQL level are these represented as distinct rows.
The wide row data structure
Another important observation is that, at the column family level, there is no preset list of allowed cell names. The cell names we observe in alice's partition of the home_status_updates column family are derived partially from data calculated at runtime—namely, the UUID values of various status update ID columns. At the CQL level, tables must have predefined column names but no equivalent restriction exists at the column family level.
Looking closely at the cells in alice's RowKey, we observe that they are in order: first, descending by the timestamp encoded in the UUID component of the cell name, and second, alphabetically ascending by the column name component. You learned in Chapter 3, Organizing Related Data that clustering columns give CQL rows a natural ordering, and now we know how the cells grouped under a given RowKey at the column family level are always ordered by the cell name.
The data structure that we observe at alice's RowKey in home_status_updates is commonly called a
wide row. Not to be confused with the rows we commonly interact with in CQL tables, wide rows are simply ordered collections of cells; each wide row is associated with a RowKey, which at the CQL level we call a partition key.
The empty cell
We've so far ignored one curious entity in the column family data structure—each RowKey seems to have a cell whose value is empty, and whose name consists purely of a clustering column value and a delimiter.
Recall that, in a CQL row, there is no requirement that any data column contain data. A row consisting purely of values for the primary key columns is entirely valid. CQL makes this possible by storing an extra cell any time a row is created or updated that acts as a placeholder indicating that there is a row in the clustering column encoded in the cell's name. Thus, the existence of the row is guaranteed even if there is no data column to be stored as a cell in that row.





