A web page is not only a document container. Today's rapid developments in computing and web technologies have transformed the web into a dynamic and real-time source of information.
At our end, we (the users) use web browsers (such as Google Chrome, Firefox Mozilla, Internet Explorer, and Safari) to access information from the web. Web browsers provide various document-based functionalities to users and contain application-level features that are often useful to web developers.
Web pages that users view or explore through their browsers are not only single documents. Various technologies exist that can be used to develop websites or web pages. A web page is a document that contains blocks of HTML tags. Most of the time, it is built with various sub-blocks linked as dependent or independent components from various interlinked technologies, including JavaScript and CSS.
An understanding of the general concepts of web pages and the techniques of web development, along with the technologies found inside web pages, will provide more flexibility and control in the scraping process. A lot of the time, a developer can also employ reverse engineering techniques.
Reverse engineering is an activity that involves breaking down and examining the concepts that were required to build certain products. For more information on reverse engineering, please refer to the GlobalSpec article, How Does Reverse Engineering Work?, available at https://insights.globalspec.com/article/7367/how-does-reverse-engineering-work.
Here, we will introduce and explore a few of the techniques that can help and guide us in the process of data extraction.
Hyper Text Transfer Protocol (HTTP) is an application protocol that transfers resources such as HTML documents between a client and a web server. HTTP is a stateless protocol that follows the client-server model. Clients (web browsers) and web servers communicate or exchange information using HTTP Requests and HTTP Responses:
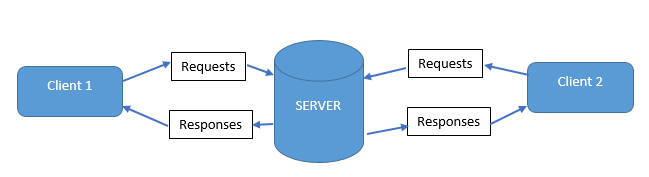
HTTP (client-server communication)
With HTTP requests or HTTP methods, a client or browser submits requests to the server. There are various methods (also known as HTTP request methods) for submitting requests, such as GET, POST, and PUT:
- GET: This is a common method for requesting information. It is considered a safe method, as the resource state is not altered. Also, it is used to provide query strings such as http://www.test-domain.com/, requesting information from servers based on the id and display parameters sent with the request.
- POST: This is used to make a secure request to a server. The requested resource state can be altered. Data posted or sent to the requested URL is not visible in the URL, but rather transferred with the request body. It's used to submit information to the server in secure way, such as for login and user registration.
Using the browser developer tools shown in the following screenshot, the Request Method can be revealed, along with other HTTP-related information:

General HTTP headers (accessed using the browser developer tools)
We will explore more about HTTP methods in Chapter 2,
Python and the Web – Using urllib and Requests, in the Implementing HTTP methods section.
HTTP headers pass additional information to a client or server while performing a request or response. Headers are generally name-value pairs of information transferred between a client and a server during their communication, and are generally grouped into request and response headers:
- Request Headers: These are headers that is used for making requests. Information such as language and encoding requests -*, that is referrers, cookies, browser-related information, and so on, is provided to the server while making the request. The following screenshot displays the Request Headers obtained from browser developer tools while making a request to https://www.python.org:

Request headers (accessed using the browser developer tools)
- Response Headers: These headers contain information about the server's response. Information regarding the response (including size, type, and date) and the server status is generally found in Response Headers. The following screenshot displays the Response Headers obtained from the browser developer tools after making a request to https://www.python.org:
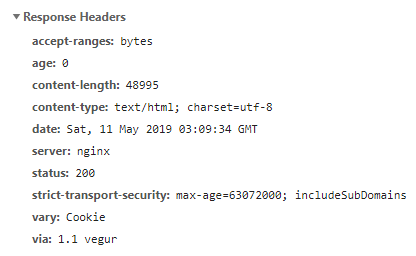
Response headers (accessed using the browser developer tools)
The information seen in the previous screenshots was captured during the request made to https://www.python.org.
HTTP Requests can also be provided with the required HTTP Headers while making requests to the server. Information related to the request URL, request method, status code, request headers, query string parameters, cookies, POST parameters, and server details can generally be explored using HTTP Headers information.
With HTTP responses, the server processes the requests, and sometimes the specified HTTP headers, that are sent to it. When requests are received and processed, it returns its response to the browser.
A response contains status codes, the meaning of which can be revealed using developer tools, as seen in the previous screenshots. The following list contains a few status codes along with some brief information:
- 200 (OK, request succeeded)
- 404 (Not found; requested resource cannot be found)
- 500 (Internal server error)
- 204 (No content to be sent)
- 401 (Unauthorized request was made to the server)
HTTP cookies are data sent by server to the browser. Cookies are data that's generated and stored by websites on your system or computer. Data in cookies helps to identify HTTP requests from the user to the website. Cookies contain information regarding session management, user preferences, and user behavior.
The server identifies and communicates with the browser based on the information stored in the cookie. Data stored in cookies helps a website to access and transfer certain saved values such as session ID, expiration date and time, and so on, providing quick interaction between the web request and the response:

Cookies set by a website (accessed using the browser developer tools)
With HTTP proxies, a proxy server acts as an intermediate server between a client and the main web server. The web browser sends requests to the server that are actually passed through the proxy, and the proxy returns the response from the server to the client.
Proxies are often used for monitoring/filtering, performance improvement, translation, and security for internet-related resources. Proxies can also be bought as a service, which may also be used to deal with cross-domain resources. There are also various forms of proxy implementation, such as web proxies (which can be used to bypass IP blocking), CGI proxies, and DNS proxies.
Cookie-based parameters that are passed in using GET requests, HTML form-related POST requests, and modifying or adapting headers will be crucial in managing code (that is, scripts) and accessing content during the web scraping process.
Details on HTTP, headers, cookies, and so on will be explored more in the upcoming Data finding techniques for the web section. Please visit MDN web docs-HTTP (
https://developer.mozilla.org/en-US/docs/Web/HTTP) for more detailed information on HTTP.
Websites are made up of pages or documents containing text, images, style sheets, and scripts, among other things. They are often built with markup languages such as Hypertext Markup Language (HTML) and Extensible Hypertext Markup Language (XHTML).
HTML is often termed as the standard markup language used for building a web page. Since the early 1990s, HTML has been used independently, as well as in conjunction with server-based scripting languages such as PHP, ASP, and JSP.
XHTML is an advanced and extended version of HTML, which is the primary markup language for web documents. XHTML is also stricter than HTML, and from the coding perspective, is an XML application.
HTML defines and contains the contents of a web page. Data that can be extracted, and any information-revealing data sources can be found inside HTML pages within a predefined instruction set or markup elements called tags. HTML tags are normally a named placeholder carrying certain predefined attributes.
HTML elements (also referred to as document nodes) are the building block of web documents. HTML elements are built with a start tag, <..>, and an end tag, </..>, with certain contents inside them. An HTML element can also contain attributes, usually defined as attribute-name = attribute-value, that provide additional information to the element:
<p>normal paragraph tags</p>
<h1>heading tags there are also h2, h3, h4, h5, h6</h1>
<a href="https://www.google.com">Click here for Google.com</a>
<img src="myphoto1.jpg" width="300" height="300" alt="Picture" />
<br />
The preceding code can be broken down as follows:
- The <p> and <h1> HTML elements contain general text information (element content) with them.
- <a> is defined with an href attribute that contains the actual link, which will be processed when the text Click here for Google.com is clicked. The link refers to https://www.google.com/.
- The <img> image tag also contains a few attributes, such as src and alt, along with their respective values. src holds the resource, that is, the image address or image URL as an value, whereas alt holds value for alternative text for <img>.
- <br /> represents a line break in HTML, and has no attribute or text content. It is used to insert a new line in the layout of the document.
HTML elements can also be nested in a tree-like structure with a parent-child hierarchy:
<div>
<p id="mainContent" class="content">
<i> Paragraph contents </i>
<img src="mylogo.png" id="pageLogo" class="logo"/>
….
</p>
<p class="content" id="subContent">
<i style="color:red"> Sub paragraph content </i>
<h1 itemprop="subheading">Sub heading Content! </h1>
….
</p>
</div>
As seen in the preceding code, two <p> child elements are found inside an HTML <div> block. Both child elements carry certain attributes and various child elements as their contents. Normally, HTML documents are built with this aforementioned structure.
HTML elements can contain some additional information, such as key/value pairs. These are also known as HTML element attributes. Attributes holds values and provide identification, or contain additional information that can be helpful in many aspects during scraping activities such as identifying exact web elements and extracting values or text from them, traversing through elements and more.
There are certain attributes that are common to HTML elements or can be applied to all HTML elements as follows. These attributes are identified as global attributes (https://developer.mozilla.org/en-US/docs/Web/HTML/Global_attributes):
HTML elements attributes such as id and class are mostly used to identify or format individual elements, or groups of elements. These attributes can also be managed by CSS and other scripting languages.
id attribute values should be unique to the element they're applied to. class attribute values are mostly used with CSS, providing equal state formatting options, and can be used with multiple elements.
Attributes such as id and class are identified by placing # and . respectively in front of the attribute name when used with CSS, traversing, and parsing techniques.
HTML element attributes can also be overwritten or implemented dynamically using scripting languages.
As displayed in following examples, itemprop attributes are used to add properties to an element, whereas data-* is used to store data that is native to the element itself:
<div itemscope itemtype ="http://schema.org/Place">
<h1 itemprop="univeristy">University of Helsinki</h1>
<span>Subject:
<span itemprop="subject1">Artificial Intelligence</span>
</span>
<span itemprop="subject2">Data Science</span>
</div>
<img class="dept" src="logo.png" data-course-id="324" data-title="Predictive Aanalysis" data-x="12345" data-y="54321" data-z="56743" onclick="schedule.load()">
</img>
HTML tags and attributes are a major source of data when it comes to extraction.
In the chapters ahead, we will explore these attributes using different tools. We will also perform various logical operations and use them to extract content.
Extensible Markup Language (XML) is a markup language used for distributing data over the internet, with a set of rules for encoding documents that are readable and easily exchangeable between machines and documents.
XML can use textual data across various formats and systems. XML is designed to carry portable data or data stored in tags that is not predefined with HTML tags. In XML documents, tags are created by the document developer or an automated program to describe the content they are carrying.
The following code displays some example XML content. The <employees> parent node has three <employee> child nodes, which in turn contain the other child nodes <firstName>, <lastName>, and <gender>:
<employees>
<employee>
<firstName>Rahul</firstName>
<lastName>Reddy</lastName>
<gender>Male</gender>
</employee>
<employee>
<firstName>Aasira</firstName>
<lastName>Chapagain</lastName>
<gender>Female</gender>
</employee>
<employee>
<firstName>Peter</firstName>
<lastName>Lara</lastName>
<gender>Male</gender>
</employee>
</employees>
XML is an open standard, using the Unicode character set. XML is used for sharing data across various platforms and has been adopted by various web applications. Many websites use XML data, implementing its contents with the use of scripting languages and presenting it in HTML or other document formats for the end user to view.
Extraction tasks from XML documents can also be performed to obtain the contents in the desired format, or by filtering the requirement with respect to a specific need for data. Plus, behind-the-scenes data may also be obtained from certain websites only.
JavaScript is a programming language that's used to program HTML and web applications that run in the browser. JavaScript is mostly preferred for adding dynamic features and providing user-based interaction inside web pages. JavaScript, HTML, and CSS are among the most commonly used web technologies, and now they are also used with headless browsers. The client-side availability of the JavaScript engine has also strengthened its position in application testing and debugging.
JavaScript code can be added to HTML using <script> or embedded as a file. <script> contains programming logic with JavaScript variables, operators, functions, arrays, loops, conditions, and events, targeting the HTML Document Object Model (DOM):
<!DOCTYPE html>
<html>
<head>
<script>
function placeTitle() {
document.getElementById("innerDiv").innerHTML = "Welcome to WebScraping";
}
</script>
</head>
<body>
<div>Press the button: <p id="innerDiv"></p></div>
<br />
<button id="btnTitle" name="btnTitle" type="submit" onclick="placeTitle()">
Load Page Title!
</button>
</body>
</html>
Dynamic manipulation of HTML contents, elements, attribute values, CSS, and HTML events with accessible internal functions and programming features makes JavaScript very popular in web development. There are many web-based technologies related to JavaScript, including JSON, jQuery, AngularJS, and AJAX, among many more.
jQuery is a JavaScript library that addresses incompatibilities across browsers, providing API features to handle the HTML DOM, events, and animations.
jQuery has been acclaimed globally for providing interactivity to the web and the way JavaScript was used to code. jQuery is lightweight in comparison to JavaScript framework, it is also easy to implement, with a short and readable coding approach.
Asynchronous JavaScript and XML (AJAX) is a web development technique that uses a group of web technologies on the client side to create asynchronous web applications. JavaScript XMLHttpRequest (XHR) objects are used to execute AJAX on web pages and load page content without refreshing or reloading the page. Please visit AJAX W3Schools (https://www.w3schools.com/js/js_ajax_intro.asp) for more information on AJAX.
From a scraping point of view, a basic overview of JavaScript functionality will be valuable to understanding how a page is built or manipulated, as well as identifying the dynamic components used.
JavaScript Object Notation (JSON) is a format used for storing and transporting data from a server to a web page. It is language independent and is popular in web-based data-interchange actions due to its size and readability.
JSON data is normally a name/value pair that is evaluated as a JavaScript object and follows JavaScript operations. JSON and XML are often compared, as they both carry and exchange data between various web resources. JSON is also ranked higher than XML for its structure, which is simple, readable, self-descriptive, understandable, and easy to process. For web applications using JavaScript, AJAX, or RESTful services, JSON is preferred over XML due to its fast and easy operation.
JSON and JavaScript objects are interchangeable. JSON is not a markup language and it doesn't contain any tags or attributes. Instead, it is a text-only format that can be sent to/accessed through a server, as well as being managed by any programming language. JSON objects can also be expressed as arrays, dictionary, and lists as seen in the following code:
{"mymembers":[
{ "firstName":"Aasira", "lastName":"Chapagain","cityName":"Kathmandu"},
{ "firstName":"Rakshya", "lastName":"Dhungel","cityName":"New Delhi"},
{ "firstName":"Shiba", "lastName":"Paudel","cityName":"Biratnagar"},
{ "firstName":"Rahul", "lastName":"Reddy","cityName":"New Delhi"},
{ "firstName":"Peter", "lastName":"Lara","cityName":"Trinidad"}
]}
JSON Lines: This is a JSON-like format where each line of a record is a valid JSON value. It is also known as newline-delimited JSON, that is, individual JSON records separated by newline (\n) characters. JSON Lines formatting can be very useful when dealing with a large volume of data.
Data sources in the JSON or JSON Lines formats are preferred to XML because of the easy data pattern and code readability, which can also be managed with minimum programming effort:
{"firstName":"Aasira", "lastName":"Chapagain","cityName":"Kathmandu"}
{"firstName":"Rakshya", "lastName":"Dhungel","cityName":"New Delhi"}
{"firstName":"Shiba", "lastName":"Paudel","cityName":"Biratnagar"}
{"firstName":"Rahul", "lastName":"Reddy","cityName":"New Delhi"}
{"firstName":"Peter", "lastName":"Lara","cityName":"Trinidad"}
From the perspective of data extraction, because of the lightweight and simple structure of the JSON format, web pages use JSON content with their scripting technologies to add dynamic features.
The web-based technologies we have introduced so far deal with content, content binding, content development, and processing. Cascading Style Sheets (CSS) describes the display properties of HTML elements and the appearance of web pages. CSS is used for styling and providing the desired appearance and presentation of HTML elements.
Developers/designers can control the layout and presentation of a web document using CSS. CSS can be applied to a distinct element in a page, or it can be embedded through a separate document. Styling details can be described using the <style> tag.
The <style> tag can contain details targeting repeated and various elements in a block. As seen in the following code, multiple <a> elements exist and also possess the class and id global attributes:
<html>
<head>
<style>
a{color:blue;}
h1{color:black; text-decoration:underline;}
#idOne{color:red;}
.classOne{color:orange;}
</style>
</head>
<body>
<h1> Welcome to Web Scraping </h1>
Links:
<a href="https://www.google.com"> Google </a>
<a class='classOne' href="https://www.yahoo.com"> Yahoo </a>
<a id='idOne' href="https://www.wikipedia.org"> Wikipedia </a>
</body>
</html>
Attributes that are provided with CSS properties or have been styled inside <style> tags in the preceding code block will result in the output seen here:

HTML output (with the elements styled using CSS)
CSS properties can also appear in in-line structure with each particular element. In-line CSS properties override external CSS styles. The CSS color property has been applied in-line to elements. This will override the color value defined inside <style>:
<h1 style ='color:orange;'> Welcome to Web Scraping </h1>
Links:
<a href="https://www.google.com" style ='color:red;'> Google </a>
<a class='classOne' href="https://www.yahoo.com"> Yahoo </a>
<a id='idOne' href="https://www.wikipedia.org" style ='color:blue;'> Wikipedia </a>
CSS can also be embedded in HTML using an external stylesheet file:
<link href="http://..../filename.css" rel="stylesheet" type="text/css">
Although CSS is used for the appearance of HTML elements, CSS selectors (patterns used to select elements) often play a major role in the scraping process. We will be exploring CSS selectors in detail in the chapters ahead.
We have introduced few selected web-related technologies so far in this chapter. Let's get an overview of web frameworks by introducing AngularJS. Web frameworks deal with numerous web-related tools and are used to develop web-related resources while adopting the latest methodologies.
AngularJS (also styled as Angular.js or Angular) is mostly used to build client-side web applications. This is a framework based on JavaScript. AngularJS is added to HTML using the <script> tag, which extends HTML attributes as directives and binds data as expressions. AngularJS expressions are used to bind data to HTML elements retrieved from static or dynamic JSON resources. AngularJS directives are prefixed with ng-.
AngularJS is used with HTML for dynamic content development. It provides performance improvement, a testing environment, manipulation of elements, and data-binding features, and helps to build web applications in the model-view-controller (MVC) framework by offering a more dynamic and flexible environment across documents, data, platforms, and other tools.
We can link external JavaScript files to our HTML document as follows:
<!doctype html>
<html ng-app>
<head>
<script
src="https://ajax.googleapis.com/ajax/libs/angularjs/1.7.5/angular.min.js">
</script>
</head>
<body>
<div>
<label> Place: </label>
<input type="text" ng-model="place" placeholder="Visited place!">
<label> Cost :</label>
<input type="text" ng-model="price" placeholder="Ticket Price!">
<br>
<b>Wow! {{place}} for only {{price}}</b>
</div>
</body>
</html>
Also, we can include the script and element blocks together on a page, as seen here:
<script>
var app = angular.module('myContact', []);
app.controller('myDiv', function($scope) {
$scope.firstName = "Aasira";
$scope.lastName = "Chapagain";
$scope.college= "London Business School";
$scope.subject= "Masters in Analytics and Management";
});
</script>
<div ng-app="myContact" ng-controller="myDiv">
First Name: <input type="text" ng-model="firstName"><br>
Last Name: <input type="text" ng-model="lastName"><br>
College Name: <input type="text" ng-model="college"><br>
Subjects: <input type="text" ng-model="subject"><br>
<br>
Full Name: {{firstName + " " + lastName}}
<br>
Enrolled on {{college + " with " + subject}}
</div>
The general overview that we've provided here of AngularJS and its working methodology allows more flexibility in tracing and traversing data.
The technologies discussed previously are a few core components of the web; they are linked, dependent on each other to produce the websites or web documents that end users interact with. In the chapters ahead, we will identify scripts and further analyze the code contained within.
In the following section, we will explore web content and look for the data that can be found inside web pages, which we will be extracting in the chapters ahead using the Python programming language.



































































