























































Making predictions
In the previous section, we set up our Docker container, and now, in this section, we'll be using our Docker container to run a REST server and make predictions. We're going to be running our Docker container that we just created and then look at the connected built-in user interface to test our REST service. Finally, we'll post an image with that REST service so that we can see a prediction come back. We'll also see how you can call through to your service with curl, a command-line program that can post files.
Now, we're going to be starting up our Docker container. We'll be mapping the local port 5000 through to the container port 5000, which is the default in our REST service. Then, we'll start the service up. The kerasvideo-server container is the one we just created, and this container will take a second to start up and import TensorFlow. Then, we will load the model and serve it off of the local IP address on port 5000:
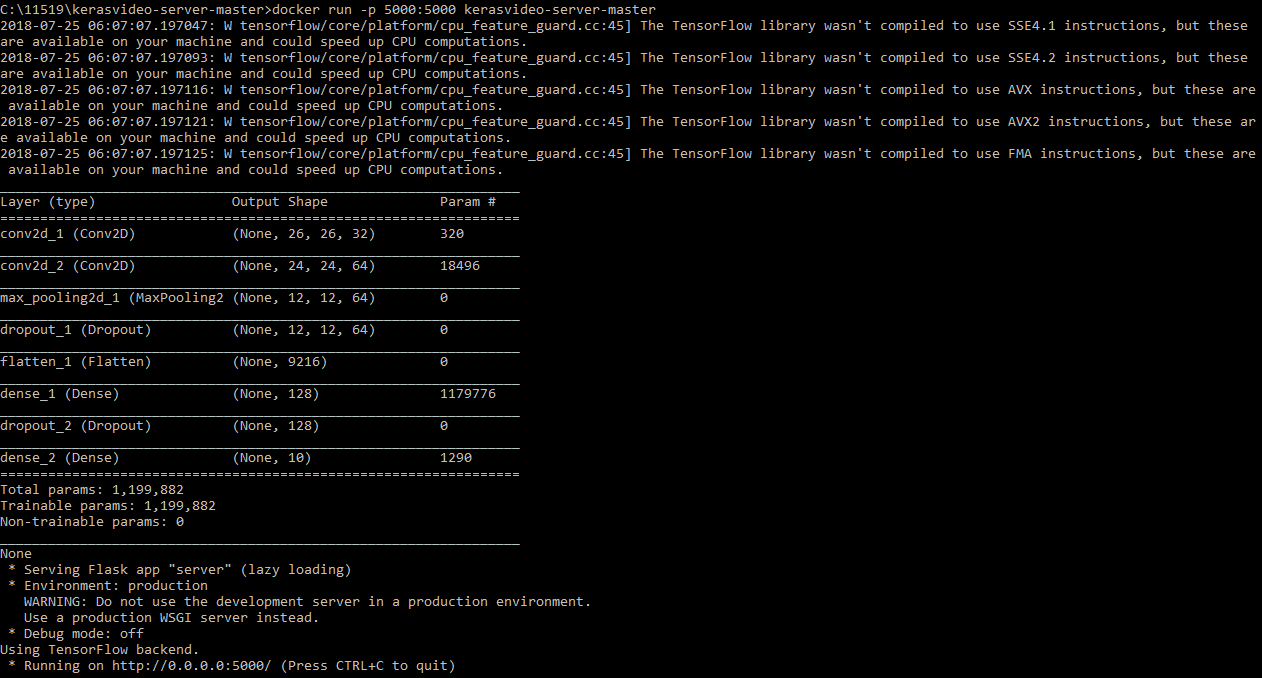
Loading of the model
So, we open up localhost...










