Revisiting the OpenStack ecosystem
OpenStack has been designed to be deployed on a loosely coupled architectural layout. By defining each component of its ecosystem to run independently, it becomes possible to distribute each service among dedicated machines to achieve redundancy. As defined, the base services that constitute the core components in OpenStack are compute, network, and storage services. Based on this, the OpenStack community takes advantage of the base services and the design approach of the cloud software, and keeps developing and joining new open source projects to the OpenStack ecosystem. A variety of new X-As-A-Service projects appear with nearly every OpenStack release.
Getting up to speed with expanding the private cloud setup involves getting to grips core OpenStack services and terms. The following table shows the main projects in OpenStack in its early releases with their corresponding code names:
Code name | Service | Description |
Nova | Compute | Manages instance resources and operations |
Glance | Image | Manages instance disk images and their snapshots |
Swift | Object storage | Manages access to object storage level through REST API |
Cinder | Block storage | Manages volumes for instances |
Neutron | Network | Manages network resources to instances |
Keystone | Identity | Manages authentication and authorization for users and services |
Horizon | Dashboard | Exposes a graphical user interface to manage an OpenStack environment |
Of course, the evolution of the OpenStack ecosystem has kept growing to cover more projects and include more services. Since October 2013 (the date of Havana's release), the OpenStack community has shifted to enlarge the services provided by OpenStack within an exhaustive list. The following table shows the extended services of OpenStack (Mitaka release) at the time of writing:
Code name | Service | Description |
Ceilometer | Telemetry | Provides monitoring of resource usage |
Heat | Orchestration | Manages the collection of resources as single unit using template files |
Trove | Database | Database as a Service (DBaaS) component |
Sahara | Elastic Data Processing (EDP) | Quickly provisions the Hadoop cluster to run an EDP job against it |
Ironic | Bare-metal | Provisions bare metal machines |
Zaqar | Messaging service | Enables notification and messaging services |
Manilla | Shared filesystems | Provides shared File system As A Service (FSaaS), allowing to mount one shared filesystem across several instances |
Designate | Domain name service | Offers DNS services |
Barbican | Key management | Provides key management service capabilities, such as keys, certificates, and binary data |
Murano | Application catalog | Exposes an application catalog allowing the publishing of cloud-ready applications |
Magnum | Containers | Introduces Container as a Service (CaaS) in OpenStack |
Congress | Governance | Maintains compliance for enterprise policies |
Note
At the official OpenStack website, you can find a very informative page project-navigator that shows the maturity and adoption statistics for each OpenStack project and the age in years in which it has been in development. You can find this website at https://www.openstack.org/software/project-navigator.
Ultimately, if you want to expand your OpenStack environment to provide more X-As-A-Service user experience, you may need to revisit the core ecosystem first. This will enable you to pinpoint how the new service will be exposed to the end user and predict any change that needs more attention regarding the load and resources usage.
Grasping a first layout
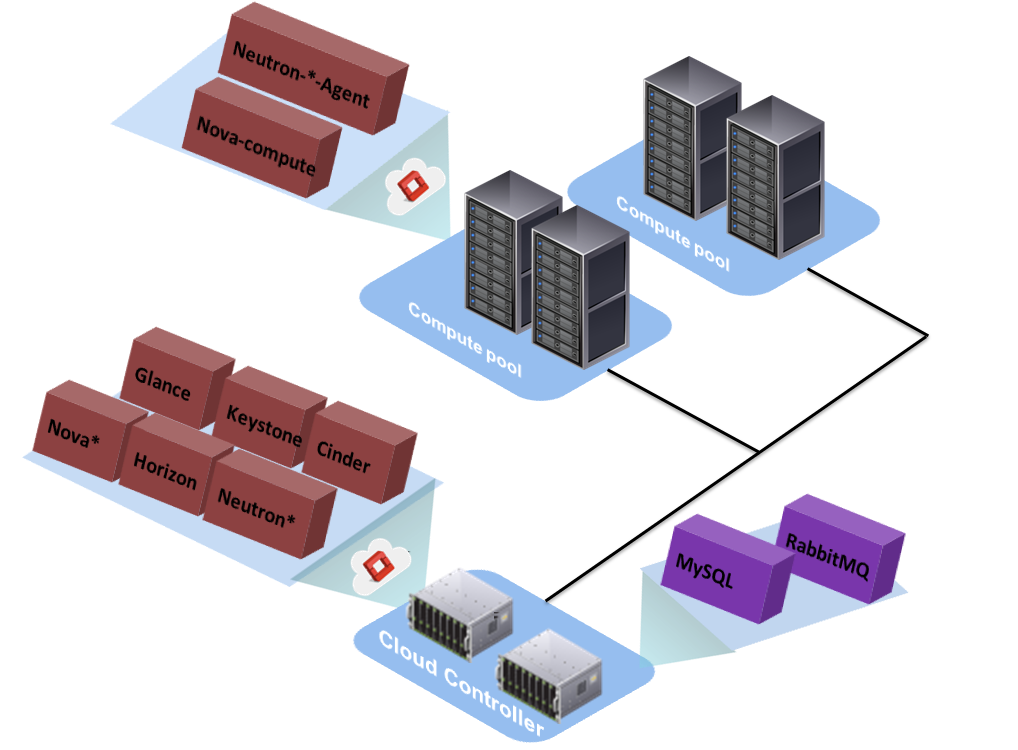
Let's rekindle the flame and implement a basic architectural design. You probably have a running OpenStack environment where you have installed its different pieces across multiple and dedicated server roles. The architectural design of the OpenStack software itself gives you more flexibility to build your own private cloud. As mentioned in the first section, the loosely coupled design makes it easier to decide how to run services on nodes in your data center. Depending on how big it is, your hardware choices, or third-party vendor dependencies, OpenStack has been built so that it can't suffer from vendor lock-in. This makes it imperative that we do not stick to any specific design pattern or any vendor requirements.
The following figure shows a basic conceptual design for OpenStack deployment in a data center: