























































Multi-Layer Perceptron
We saw that the AND and OR gate outputs are linearly separable and perceptron can be used to model this data. However, not all functions are separable. In fact, there are very few and their proportion to the total of achievable functions tends to zero as the number of bits increases. Indeed, as we anticipated, if we take the XOR gate, the linear separation is not possible. The crosses and the zeros are in different locations and we cannot put a line to separate them, as shown in the following figure:
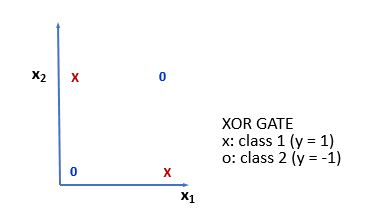
We could think of parsing more perceptrons. The resulting structure could thus learn a greater number of functions, all of which belong to the subset of linearly separable functions. In order to achieve a wider range of functions, intermediate transmissions must be introduced into the perceptron between the input layer and the output layer, allowing for some kind of internal representation of the input. The resulting perceptron is called MLP.
We have already seen this as...

















