























































Jaccard similarity calculates the similarity between two sets by the ratio of common words (intersection) to totally unique words (union) in both sets. It takes a list of unique words in each sentence or document. It is useful where the repetition of words does not matter. Jaccard similarity ranges from 0-100%; the higher the percentage, the more similar the two populations:
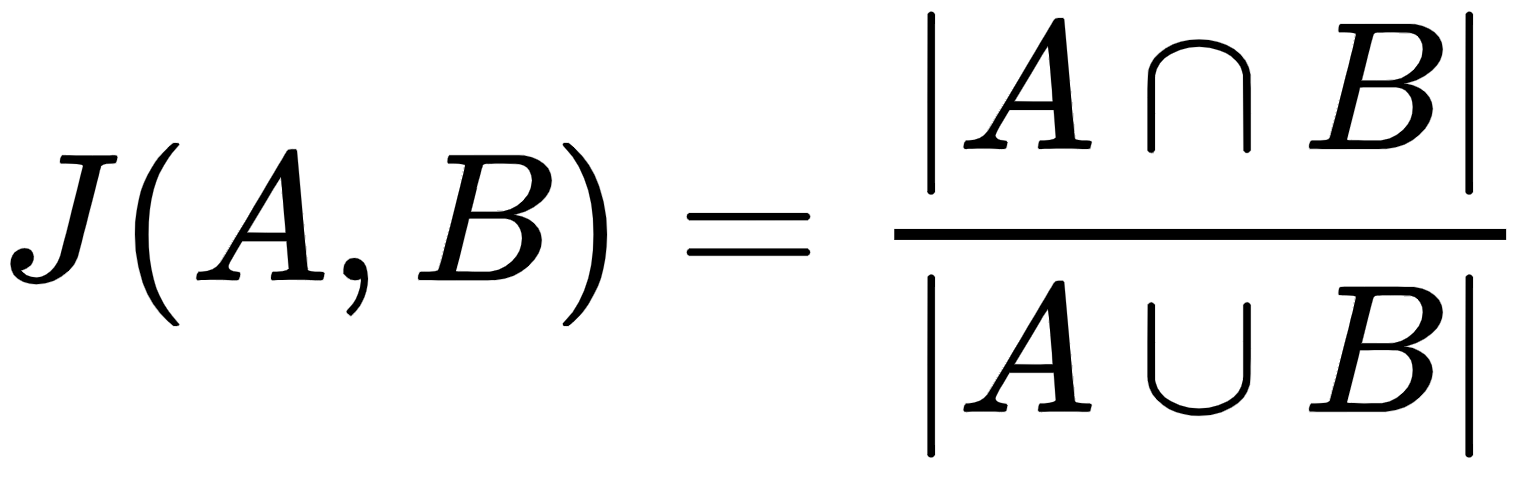
Let's look at a Jaccard similarity example:
def jaccard_similarity(sent1, sent2):
"""Find text similarity using jaccard similarity"""
# Tokenize sentences
token1 = set(sent1.split())
token2 = set(sent2.split())
# intersection between tokens of two sentences
intersection_tokens = token1.intersection(token2)
# Union between tokens of two sentences
union_tokens=token1.union(token2)
# Cosine Similarity
sim_= float(len(intersection_tokens) / len(union_tokens))
return sim_
jaccard_similarity('I love pets.',...
















