























































Gradient descent
In the examples in this chapter, we analytically solved for the values of the model's parameters that minimize the cost function with the following equation:
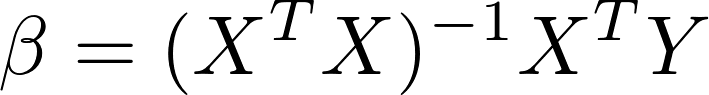
Recall that X is the matrix of features for each training example. The dot product of XTX results in a square matrix with dimensions n by n, where n is equal to the number of features. The computational complexity of inverting this square matrix is nearly cubic in the number of features. While the number of features has been small in this chapter's examples, this inversion can be prohibitively costly for problems with tens of thousands of explanatory variables, which we will encounter in the following chapters. Furthermore, it is impossible to invert X if its determinant is zero. In this section, we will discuss another method for efficiently estimating the optimal values of the model's parameters called gradient descent. Note that our definition of the goodness-of-fit has not changed; we will still use gradient descent...

















